1. THE KERNEL AT A GLANCE
1.1. Design Approach
Real-time system software, and more broadly cyber-physical software, is highly domain-specific and hardware-dependent. However, much of the industry continues to pursue commonality primarily at the hardware–software interface. These interfaces can express syntax and some semantics, which is useful, but they remain dangerously limited. On their own, they do not capture the coordination rules necessary for predictable real-time software.
RK0 adopts a different approach. The deeper commonality in cyber-physical systems lies not in the peripheral register map, board description, or driver abstraction, but in the concurrency model. Computation progresses in response to urgency, precedence, exclusion, availability, notification, and state-transfer conditions. Regardless of the domain or hardware, the application layer repeatedly faces coordination problems that are neither infinite in variety nor unknown. In this sense, RTOS services can be more expressive than generic mechanisms alone.
Many real-time kernels inherit a general-purpose habit of overgeneralisation: they provide overloaded primitives whose meaning is mostly derived from usage. This can appear neutral, but often becomes displacement. Meaning is not removed; it is pushed into the application, usually without a clear framework, where it tends to degrade into ad hoc protocols, hidden assumptions, and fragile side-effects.
RK0 does not reject generic services; it provides them where generality is beneficial. Additionally, RK0 offers services whose semantics directly encode common real-time coordination patterns. The objective is not to prevent composition, but to eliminate the need for applications to reconstruct complex real-time semantics from weak primitives.
Several concrete examples illustrate this approach:
-
RK0 provides a Message Queue that is sufficiently generic to support both blocking and non-blocking use, as well as specific operations such as send to front, peek, and overwrite, which are standard for message queues. Each queue enforces a fixed message size of 1, 2, 4, or 8 words, passed by copy. Word-sized alignment promotes type safety, low overheads, and predictable execution cost, while passing by copy enhances data integrity.
-
No API is provided for arbitrary variable-size messages. If an application requires variable-size payloads, which is common but remains strictly an application concern, a recommended pattern is to use a memory partition in conjunction with a 1-word message queue that carries pointers to pool blocks. This approach ensures that the kernel primitive remains bounded and predictable, while allowing the application to optimise for its specific requirements.
-
On the other hand, the Message Queue can be a purposeful mechanism. If the queue is supposed to have a single receiver (an owner), a recurrent worst case is that an occasional burst blocks an urgent, but sporadic, sender. Aware of ownership, the kernel raises the owner’s priority to reduce priority inversion.
-
-
Call Channels have invocation semantics and are therefore another service apart from Message Queues.
-
The Most-Recent Message protocol addresses a recurring pattern: 1:N communication in which consumers require the latest relevant state rather than a backlog of samples. Last-message semantics is necessary for responsive control structures, including cascaded or hierarchical control loops. Keeping data integrity on a 1:N fully-asynchronous (e.g., using double/triple buffering) is not trivial and is a common need.
-
Mutexes illustrate another design guideline. RK0 does not support recursive mutex locking; such attempts are treated as faults. Mutex service focuses on fully transitive priority inheritance over nested locks: a legitimate case for resource dependencies.
Nevertheless, the critical factor is not only recognising common concurrency needs as a kernel concern, but also handle their worst-case scenarios.
2. Real-time and communication model
2.1. Tasks and Scheduling Policy
A Task is the concurrency unit in RK0. It follows the Thread model.
A static task assumes the states INITIALISED, READY, RUNNING, WAITING — the last is split into different pseudo-states. A dynamic task (explained later) adds a TERMINATED state.
Aside from design details, functionally the scheduler is a priority-based preemptive — quite standard.
A major difference is that it deliberately has no built-in time-slice.
The scheduler is the only unit allowed to switch a task from READY to RUNNING. Combined with no built-in time-slicing, we claim:
Execution progress is expressed in the application code.
Knowing the that the READY tasks are within a table of FIFO Queues, and each row is related to a priority, we define an invariant:

The highest priority ready task is at the head of highest priority non-empty ready queue.
All tasks run under the same policy:
-
A task must switch to the READY state before being eligible for scheduling.
-
Only the Scheduler can switch a task from READY to RUNNING.
-
A task will switch from RUNNING to READY if yielding or if being preempted by a higher priority task. Otherwise it can only go to a WAITING state, and eventually switch back to READY.
-
When a task is preempted by a higher priority task, it switches from RUNNING to READY and is placed back on the head position of its Ready Queue. This means that it will be resumed as soon as it is the highest priority ready task again.
-
On the contrary, if a task yields, it tells the scheduler it has completed its cycle. Then, it will be enqueued on the ready queue tail — the last queue position.
-
WAITING means the Task is suspended until a condition is satisfied. Once the condition is true, it transitions to the READY state, enqueued on the tail of its ready queue.
-
So, tasks with the same priority cooperate by either yielding or waiting.
-
If a task is dispatched and never yields or waits, the scheduler will correctly keep it running, while there is no higher priority READY task. It is not incidental starvation: no reason to progress differently was expressed in the application. This idea is not strange: it is sequential logic.
-
Finally, Tasks with the same priority are initially placed on the Ready Queue associated with that priority in the order they are created.
PS: tasks are allowed to be created as non-preemptible, for exceptional cases the application might need.
2.2. Events, Signals and Messages
A system has state variables that determine its behaviour. A change in a state variable is caused by an event. The periodic hardware interrupt (SysTick) that increments the kernel runtime count is an example.
The notion of execution progress on a digital computer arises from observable changes in state, whatever those states represent. Therefore, given two observation logical instants, if the observed state differs, at least one event must have occurred in (real) time. Note that if there is no difference, we can’t state that no event has happened.
In this sense, an event is a logical construct derived from observed reality. Time runs on a continuum; the computer samples reality with varying granularity. Computation, therefore, always lags. Aware of that, a real-time system’s goal is to react to external stimuli so that a result is delivered to the environment while it is still useful.
On a real-time kernel, execution progress follows the urgency of tasks and precedence conditions. We design concurrent units (Tasks) and use kernel services to coordinate their execution, ensuring they are ordered and that they produce a time-bounded final response.
Inter-task Communication mechanisms are in charge of this coordination. In RK0 tasks send/receive information in the form of Signals or Messages.
A Signal (or a Signal token) signifies an occurrence. When a task checks for a signal, it is sufficient that the signal be present for the task to proceed. The operation of signalling another task does not affect the sender task. A signal is a notification, never a 'request'.
A Message conveys structured, variable information. The progress emerges from how the sender and receiver handle information in messages, as well as from the mechanism itself as described in this page.
You might want to read this document along with the Current public Services API and the Service Map
2.3. Suitable Applications
RK0 targets applications with the following characteristics:
-
They are designed to handle particular devices in which real-time responsiveness is imperative.
-
Applications and middleware may be implemented alongside appropriate drivers.
-
Drivers may even include the application itself.
-
Untested programs are not loaded: After the software has been tested, it can be assumed reliable.
3. Architecture
The layered architecture can be split — roughly — into two: a top and a bottom layer. On the top, the Executive manages the resources needed by the application.
On the bottom, the Low-level Scheduler works as a software extension of the CPU.
Together, they implement the Task abstraction. This primitive is the Concurrency Unit and follows the Thread model. A Task is a Thread

In systems design jargon, the Executive enforces policy (what should happen). The Low-level Scheduler provides the mechanism (how it gets done). The services are the primitives that gradually translate policy decisions into concrete actions executed by the Scheduler.
RK0’s goal is determinism on low-end devices. Its multitasking engine does not split user space from kernel space. Tasks execute in privileged mode and use a dedicated process stack pointer, distinct from the system stack. The rationale:
-
Application tasks are not unknown entities at run time.
-
Implementing system calls as traps increases complexity in critical control paths, degrading determinism.
-
Relying on the ARMv6/7-M MPU decreases memory usage efficiency and introduces latency on control paths. It does not fit RK0’s deterministic execution model.
3.1. Scheduler Design Internals
A notable scheduler characteristic is its constant-time complexity (O(1), for 'choose-next' operation) with low latency.
This was achieved by carefully composing the data structures and algorithms.
|
RK0 can handle context-switching with an extended frame when a float-point co-processor is available. This must be informed when compiling by defining the symbol |
3.1.1. Task Control Block
Every primitive is associated to a data structure we refer to as its Control Block. A Task Control Block is a record for stack, resources, and time management. The table below partially represents a Task Control Block (as this document is live, this might not reflect the exact fields of the current version).
| Task Control Block |
|---|
Task name |
Task ID |
Status |
Assigned Priority |
Effective Priority |
Saved Stack Pointer |
Stack Address |
Stack Size |
Last wake-time |
Next wake-time |
Time-out Flag |
Preemption Flag |
Owned Resources List |
Waiting Resources List |
Event Register Control Block |
Mesg Queue Address (Port) |
Channel Address |
Timeout List Node |
TCB List Node |

3.1.2. Task Queues
The backbone of the queues where tasks will wait for their turn to run is a circular doubly linked list: removing any item from a double list takes O(1) (provided we don’t need to search the item). As the kernel knows each task’s address, adding and removing is always O(1). Singly linked lists can’t achieve O(1) for removal.
3.1.3. Ready Queue Table
Another design choice to achieve O(1) is the global ready queue, which is a table of FIFO queues—each queue dedicated to a priority—and not a single ordered queue. So, enqueuing a ready task is always O(1). Given the sorting needed, the time complexity would be O(n) if tasks were placed on a single ready queue.
3.1.4. Waiting Queues
The scheduler does not have a unique waiting queue. Every kernel object that can block a task has an associated waiting queue. Because these queues are a scheduler component, they follow a priority discipline: the highest priority task is dequeued first, always.
When an event capable of switching tasks from WAITING to READY happens, one or more tasks (depending on the mechanism) are then placed on the ready list, unique to their priority. Now, they are waiting to be picked by the scheduler—that is the definition of READY.
3.1.5. The choose-next algorithm
As the ready queue table is indexed by priority - the index 0 points to the queue of ready tasks with priority 0, and so forth, and there are 32 possible priorities - a 32-bit integer can represent the state of the ready queue table. It is a BITMAP:
The BITMAP update happens whenever:
(1a) A task is readied, update: BITMAP |= (1U << task->priority);
(1b) An empty READY QUEUE becomes non-empty, update: BITMAP |= (1U << queueIndex)
(2): Every Time READY QUEUE becomes empty, update: BITMAP &= ~(1U << queueIndex);
EXAMPLE:
Ready Queue Index : (6)5 4 3 2 1 0
Not empty : 1 1 1 0 0 1 0
------------->
(LOW) Effective Priority (HIGH)
In this case, the scenario is a system with 7 priority task levels. Queues with priorities 6, 5, 4, and 1 are not empty.Having the Ready Queue Table bitmap, we find the highest priority non-empty task list as follows:
(1) Isolate the rightmost '1':
RBITMAP = BITMAP & -BITMAP. (- is the bitwise operator for two's complement: ~BITMAP + 1) `In this case:
[31] [0] : Bit Position
0...1110010 : BITMAP
1...0001110 : -BITMAP
=============
0...0000010 : RBITMAP
[1]The rationale here is that, for a number N, its 2’s complement -N, flips all bits - except the rightmost '1' (by adding '1') . Then, N & -N results in a word with all 0-bits except for the less significant '1'.
(2) Extract the rightmost '1' position:
-
For ARMv7M, we benefit from the
CLZinstruction to count the leading zeroes. As they are the number of zeroes on the left of the rightmost bit, '1', this value is subtracted from 31 to find the Ready Queue index.
unsigned __getReadyPrio(unsigned readyQBitmap)
{
unsigned ret;
__ASM volatile (
"clz %0, %1 \n"
"neg %0, %0 \n"
"add %0, %0, #31\n"
: "=&r" (ret)
: "r" (readyQBitmap)
:
);
return (ret);
}This instruction would return #30, and #31 - #30 = #01 in the example above.
-
For ARMv6M there is no suitable hardware instruction. The algorithm is written in C and counts the trailing zeroes, thus, the index number. Although it might vary depending on your compiler settings, it takes ~11 cycles (note it is still O(1)):
/*
De Brujin's multiply+LUT
(Hacker's Delight book)
*/
/* table is on a ram section for efficiency */
const static unsigned readyPrioTbl[32] =
{
0, 1, 28, 2, 29, 14, 24, 3, 30, 22, 20, 15, 25, 17, 4, 8,
31, 27, 13, 23, 21, 19, 16, 7, 26, 12, 18, 6, 11, 5, 10, 9
};
RK_FORCE_INLINE static inline
unsigned __getReadyPrio(unsigned readyQBitmap)
{
unsigned mult = readyQBitmap * 0x077CB531U;
/* Shift right the top 5 bits
*/
unsigned idx = (mult >> 27);
/* LUT */
unsigned ret = (unsigned)readyPrioTbl[idx];
return (ret);
}For the example above, mult = 0x2 * 0x077CB531 = 0x0EF96A62. The 5 leftmost bits (the index) are 00001 → table[1] = 1.
During a context switch, the procedures to find the highest priority non-empty ready queue table index are as follows:
static inline RK_PRIO kCalcNextTaskPrio_(VOID)
{
if (readyQBitMask == 0U)
{
return (idleTaskPrio);
}
readyQRightMask = readyQBitMask & -readyQBitMask;
RK_PRIO prioVal = (RK_PRIO) (__getReadyPrio(readyQRightMask));
return (prioVal);
}
/* O(1) complexity */
VOID kSwtch(VOID)
{
nextTaskPrio = kCalcNextTaskPrio_();
RK_TCB* nextRunPtr = NULL;
kTCBQDeq(&readyQueue[nextTaskPrio], &nextRunPtr);
runPtr = nextRunPtr;
}4. Timers
4.1. Busy-wait delay
A busy-wait delay kBusyDelay(t) or kDelay(t) means 'consume t ticks of time RUNNING'.
So, while a busy-delay is active if the task is preempted, the elapsed time to resume is not taken into account to finish the busy-wait operation.
It is useful to simulate a workload or to just delay two calls within a task without blocking.
|
Context switching is probably the most significant overhead on a kernel. The time spent on the System Tick handler contributes to much of this overhead. Design Choice:
Benefits:
|
4.2. Timeout operations
| Timeout Node |
|---|
Timeout Type |
Absolute Interval (Ticks) |
Relative Interval (Ticks) |
Waiting Queue Address |
Next Timeout Node |
Previous Timeout Node |
Every task is prone to events triggered by timers described in this section. Every Task Control Block has a node to a timeout list. This list is doubly linked treated a delta-sequence.
A set Tset = {(T1,8), (T2,6), (T3,10)} will be started at a relative time 0 as a sequence Tseq = <(T2,6), (T1,2), (T3,2)>.
Thus, for every system tick, only the head element on the list needs to be decreased — yielding O(1) on decreasing, that happens on the Hardware interrupt for the System Tick.
The ordering for the delta-queue is not O(1), it is O(n). A decrease happens on every SysTick interrupt; and the ordering happens only when adding a new node to the list.
4.2.1. Blocking Time-out
These are internal timers associated with kernel calls that are blocking. Thus, establishing an upper-bound waiting time might benefit them. When the time for unblocking is up, the kernel call returns, indicating a timeout. This value is passed as a number of ticks.
When blocking is associated with a kernel object (other than the Task Control Block), the timeout node will store the object waiting for queue’s address, so it can be removed if time expires.
A kernel call is made non-blocking, that is try semantics, by assigning the value RK_NO_WAIT, the function returns immediately if unsuccessful.
The value RK_WAIT_FOREVER suspends a task indefinitely until the condition is satisfied.
Timeout values above RK_MAX_PERIOD are invalid.
In practice, we often block either using RK_WAIT_FOREVER or do not block (try semantics, RK_NO_WAIT).
Use a bounded timeout only when you expect occasional misses and you know how to handle them.
4.2.2. Sleep Delay
The sleepdelay() (aliased as sleep()) puts a task to sleep for the exact number of t ticks on every call — no matter when the last call has happened.
Example:
VOID Task1(VOID* args)
{
RK_UNUSEARGS
UINT count = 0;
while (1)
{
logPost("Task1: sleep");
kSleep(300);
/* wake here */
count += 1U;
if (count >= 5)
{
kDelay(25); /* spin */
count=0;
/* every 5 activations there will be a drift */
}
}
}Output:
0 ms :: Task1: sleep
300 ms :: Task1: sleep <-- +300
600 ms :: Task1: sleep <-- +300
900 ms :: Task1: sleep <-- +300
1200 ms :: Task1: sleep <-- +300
1525 ms :: Task1: sleep <-- +325
1825 ms :: Task1: sleep <-- +300
2125 ms :: Task1: sleep <-- +300
2425 ms :: Task1: sleep
2725 ms :: Task1: sleep
3050 ms :: Task1: sleep
3350 ms :: Task1: sleep
3650 ms :: Task1: sleep
3950 ms :: Task1: sleep
4250 ms :: Task1: sleep
4575 ms :: Task1: sleep4.2.3. Compensated Sleep Delays
These are suspensions that recompute the time considering the drift between calls. They are typically used to create periodic tasks with explicit periods. The general pattern is:
VOID Task(VOID *args)
{
<initialisation>
while(1)
{
<periodic code>; /* this has an execution time */
scheduleNext(PERIOD); /* cycle is finished: compute delay to keep PERIOD */
}
}The RMS algorithm considers all tasks have a common phase grid, that is when they are made READY, or are eligible to be scheduled. This means that from the very first activation, the time elapsed is already take into account to when the next release should happen.
Nevertheless, it is common for kernels to provide sleep primitives that take into account a local anchor time normally set on the <initialisation> code — and will work as waitUntil(&anchor, PERIOD). RK0 provides both, and they suit different cases, as exposed below.
4.2.3.1. Sleep and Release (phase-locked)
sleeprelease(P) is used to delay a task so it is released on periodic rate.
The sleep time is recalculated by the kernel on every call.
If the task wakes late by N ticks with 0 < N < P, the kernel compensates by scheduling the next wake earlier (shortening the next sleep) so that over two periods the phase is preserved:
Say a task is expected to return from its keth sleep at Tk+1 = Tk + P [ticks]. If the task is resumed at Tk+1 = Tk + P + N, upon detecting this drift, the kernel sets: (Tk+2 = Tk+1 + P - N) for N < P.
This can be rewritten as:
(Tk+2 = Tk + P + N + P - N) ←→
(Tk+2 - Tk = 2P)
Example:
VOID Task1(VOID* args)
{
RK_UNUSEARGS
UINT count = 0;
while (1)
{
logPost("Task1 released.");
count += 1U;
if (count >= 5)
{
kDelay(25); /* spin */
count=0;
}
kSleepRelease(300); /*P=300 ticks; tick=1ms*/
}
}Output:
.
.
/* R is release time */
1200 ms :: Task1: sleep periodic (R==4P) (n)
1525 ms :: Task1: sleep periodic (5P<R<6P) |
1800 ms :: Task1: sleep periodic (6P) |
2100 ms :: Task1: sleep periodic (7P) |
2400 ms :: Task1: sleep periodic (8P) |
2700 ms :: Task1: sleep periodic (9P) |
3025 ms :: Task1: sleep periodic (10P<R<11P) |
3300 ms :: Task1: sleep periodic (11P) |
3600 ms :: Task1: sleep periodic (12P) |
3900 ms :: Task1: sleep periodic (13P) |
4200 ms :: Task1: sleep periodic (14P) |
4525 ms :: Task1: sleep periodic (15P<R<16P) |
4800 ms :: Task1: sleep periodic (16P) (m) m-n=12
. -----
. Phase=3600=12xP
.This mechanism is phase-locked. When the lateness is greater or equal to P it skips one or more releases to stay locked to the phase grid. In some sense, the period value can be seen as a deadline — if not met, the scheduler rejects to run on that activation.
sleeprelease() makes easier to perform worst-response time analysis on periodic tasks.
A set of periodic tasks must have priorities assigned properly (highest request rate, highest priority — the lower the period, the higher the priority). For sleeprelease() this is mandatory given the common phase grid.
|
4.2.3.2. Sleep Until (local scope reference)
sleepuntil(anchor, period) is somehow similar to sleeprelease(), but differs in two important aspects:
-
The reference used to calculate how long to suspend to keep its rate is local to each task. It means the time before the first time the task is dispatched is dismissed.
-
A late release longer than 1 period will return and run immediately. It prioritises execution count within a time-window - not the phase across releases.
The snippet belows clearly demonstrates how each mechanism handles lateness that are longer than 1 period:
/* Every 3rd call both tasks will add up a delay longer than the task's period */
VOID HTask(VOID* args) /* higher priority: Period is 300 ticks */
{
RK_UNUSEARGS
UINT count = 0;
while (1)
{
logPost("Higher: begin\r\n");
/* wake here */
count += 1U;
kDelay(5);
if (count >= 3)
{
kSleep(400); /* suspend */
count=0;
}
logPost("Higher: end\r\n");
kSleepRelease(300);
}
}
VOID LTask(VOID *args) /* lower priority: Period is 400 ticks */
{
RK_UNUSEARGS
RK_TICK anchor = kTickGet();
UINT count=0;
while (1)
{
logPost("Lower: begin\r\n");
/* wake here */
count += 1U;
kDelay(5);
if (count >= 3)
{
kSleep(500);
count=0;
}
logPost("Lower: end\r\n");
kSleepUntil(&anchor, 400);
}
}Output:
0 ms :: Higher: begin
5 ms :: Higher: end
5 ms :: Lower: begin
10 ms :: Lower: end
300 ms :: Higher: begin
305 ms :: Higher: end
405 ms :: Lower: begin
410 ms :: Lower: end
/* H 3rd run, expected next at 900ms */
600 ms :: Higher: begin
/* L 3rd run, expected next at 1205 ms */
805 ms :: Lower: begin
/* H Drift: 1005ms - 600ms = 405 ms > 300ms */
1005 ms :: Higher end
/* H released again @ next multiple of 300. */
1200 ms :: Higher: begin
1205 ms :: Higher: end
/* L Drift: 1310ms - 805ms = 505 ms > 400ms */
1310 ms :: Lower: end
/* it runs again immediately */
1310 ms :: Lower: begin| One normally does not write a code with periodic tasks expecting they will not keep their rate. But on the field a transient overload might cause it to happen. If it does, you choose the policy that is best-fit for your task: preserve phase (skip) or preserve execution count. |
|
Importantly, an ISR shall never block. Any blocking call from an ISR is invalid and triggers fault handling when error checking is enabled. |
4.3. Callout Timers (Application Timers)
| Timer Control Block |
|---|
Option: Reload/One-Shot |
Phase (Initial Delay) |
Callout Function Pointer |
Callout Argument |
Timeout Node |
These are Application Timers that will issue a callback when expiring.
Optionally, there is an initial phase delay, besides the option to be periodic or run once.
|
It should be clear Callout timers are for minimal urgent operations that need high time precision and in practice they run at priority that could be considered
|
5. System Tick
A dedicated peripheral that generates an interrupt after a defined period provides the kernel time reference. For ARMv6/7M, this peripheral is the built-in SysTick, a 24-bit counter timer.
The 'housekeeping' accounts for global timer tracking and any tick-dependent condition that might change a task status.
The handler performs some housekeeping on every tick. If a task whose execution progress was depending on time switches to READY the routine returns to call
the scheduler. If an application timer is due, it signals the system task that performs the installed callback and additional logic.
Although many examples here are set @ 1ms tick, 10ms is a realistic case for low-end MCUs.
6. System Tasks
System Tasks perform housekeeping and other kernel maintenance outside interrupt handlers.
Currently there are the Idle Task the PostProcSysTask.
The PostProcSysTask executes Application Timer callbacks and work deferred from ISRs, such as broadcast-style flushes on Sleep Queues.
The Idle Task runs whenever there is no other ready task to be dispatched. The IdleTask is dispatched when the Ready bitmap is 0x00000000.
7. Memory Allocator
| Memory Allocator Control Block |
|---|
Associated Block Pool |
Number of Blocks |
Block Size |
Number of Free Blocks |
Free Block List |
The standard C library malloc() leads to fragmentation and (also, because of that) is highly indeterministic. Unless we use it once - to allocate memory before starting up, it doesn’t fit. But often, we need to 'multiplex' memory amongst tasks over time, that is, to dynamically allocate and deallocate.
To avoid fragmentation, we use fixed-size memory blocks. So every RK_MEM_PARTITION kernel object controls allocation and deallocation of homogeneous blocks in memory, that can either be
of any type. For instance, data structures for a request-response
communication, or stack buffers for Tasks.
A simple approach would be a static table marking each block as free or taken. With this pattern, you will need to 'search' for the next available block, if any - the time for searching changes - bounding this search to a maximum number of blocks, or O(n). To optimise, an approach is to keep track of what is free using a dynamic table—a linked list of addresses. Now we have O(1).
We use "meta-data" to initialise the linked list. Every address holds the "next" address value. All addresses are within the range of a pool of fixed-size blocks. This approach limits the minimal size of a block to the size of a memory address—32 bits for our supported architecture.
Yet, this is the cheapest way to store meta-data. If not stored on the empty address itself, an extra 32-bit variable would be needed for each block, so it could have a size of less than 32 bits.
|
Allocating memory at runtime is a major source of latency (1), indeterministic (2) behaviour, and footprint overhead (3). Design choice: the allocator’s design achieves low-cost, deterministic, fragmentation-free memory management by using fixed-size word-aligned block sizes (1)(2) and embedding metadata within the memory blocks themselves (3). Benefits: Run-time memory allocation benefits have no real-time drawbacks. |
| The kernel will always round up the block size to the next multiple of 4. Say the user creates a memory pool, assigning blocks to be 6-byte wide; they will turn into 8-byte blocks. |
7.1. How it works
When a routine calls alloc(), the address to be returned is the one a "free list" is pointing to, say addr1. Before returning addr1 to the caller, we update the free list to point to the value stored within addr1 - say addr8 at that moment.
When a routine calls free(addr1), we overwrite whatever has been written in addr1 with the value-free list point to (if no more alloc() were issued, it would still be addr8), and addr1 becomes the free list head again.
Allocating and deallocating fixed-size blocks using this structure and storing meta-data this way is as deterministic (O(1)) and economical as we can get for dynamic memory allocation.
7.2. Usage Example: allocating and deallocating kernel objects
Dynamic tasks will be discussed on the next section. Normally when using them, you might need to also dynamically create and destroy kernel objects such as a Mutex. This is a pattern for creating/initialising and destroying safely, preventing stale pointer reuse:
/* pool of mutexes */
RK_MEM_PARTITION mutexPart;
RK_MUTEX mutexPool[MUTEX_BLOCKS] K_ALIGN(4); /* could be attributed to memory section in the linker */
RK_MUTEX *MutexCreate(VOID)
{
RK_MUTEX *mutexPtr = (RK_MUTEX *)kMemPartitionAlloc(&mutexPart);
if (mutexPtr == NULL)
{
return (NULL);
}
RK_ERR err = kMutexInit(mutexPtr, RK_INHERIT);
if (err != RK_ERR_SUCCESS)
{
/* free if couldnt initialise */
kMemPartitionFree(&mutexPart, mutexPtr);
return (NULL);
}
/* return the address allocated */
return (mutexPtr);
}
RK_ERR MutexDestroy(RK_MUTEX **mutexPPtr)
{
if ((mutexPPtr == NULL) || (*mutexPPtr == NULL))
{
return (RK_ERR_OBJ_NULL);
}
UINT state = 0U;
RK_ERR err = kMutexQuery(*mutexPPtr, &state);
if (err != RK_ERR_SUCCESS)
{
return (err);
}
/* !!! cant destroy a mutex that is still locked! */
if (state != 0U)
{
return (RK_ERR_MUTEX_LOCKED);
}
err = kMemPartitionFree(&mutexPart, *mutexPPtr);
if (err != RK_ERR_SUCCESS)
{
return (err);
}
/* !!! important: to avoid accidental reuse. */
*mutexPPtr = NULL;
return (RK_ERR_SUCCESS);
}In kApplicationInit(VOID) initialise the memory allocator:
/*parms: partition addr, pool addr, size of the object (bytes), number of objects */
kMemPartitionInit(&mutexPart, mutexPool, sizeof(mutexPool[0]),
MUTEX_BLOCKS);A task willing to create/destroy a mutex dynamically would use:
/* create */
RK_MUTEX *mutexPtr = MutexCreate();
/* test if mutexPtr != NULL */
/* destroy */
RK_ERR err = MutexDestroy(&mutexPtr);
/* test if err == SUCCESS */8. Dynamic Tasks
Dynamic Tasks are tasks that can be created and terminated after the scheduler has started and they rely on the dynamic allocation of stack buffers.
For real-time sanity, tasks created after the scheduler starts are already bad. If they are dynamic and unknown, it is a liability. This should be clear.
That said, the support for dynamic tasks as a service was made available so some 3rd party middlewares, that create tasks 'on the fly, can be integrated with less effort.'
In RK0 we call Static Tasks are those initialised (created) before the scheduler is started and will never be terminated.
Dynamic Tasks are created by other tasks. They can be terminated by other tasks and also, terminate themselves. The TERMINATED state is assigned.
This is just a mark on the TCB. The memory used by a terminated task can be recycled and assigned to a new task.
We handle each of them as follows:
-
Static/startup tasks:
-
Objects declared with
RK_DECLARE_TASK(…). -
Initialised with
kTaskInit(…). -
Require an explicit stack buffer pointer.
-
-
Dynamic/runtime tasks:
-
Objects declared with
RK_DECLARE_DYNAMIC_TASK(…). -
Backed by one or more user-defined stack partitions (fixed block size), which can be declared using
RK_DECLARE_DYNAMIC_STACK_POOL(…). -
Created with
kTaskSpawn(…)receiving anRK_DYNAMIC_TASK_ATTRdata structure. -
Its stack size depends on the Memory Pool assigned to its attributes — as each memory pool has homogeneous objects.
-
kTaskTerminate(taskHandle)is used by a task to terminate another. -
kTaskTerminateSelf()a handled by the system post-processing task.
-
/* static tasks and dynamic tasks altogether */
/* in kconfig.h the total number of supported tasks is
set to 4 in this example */
#define STACK1SIZ 128U
#define STACK2SIZ 128U
#define DYNSTACKSIZ 256U
#define N_DYN_TASKS 2U
RK_DECLARE_TASK(task1Handle, Task1, stack1,
STACK1SIZ)
RK_DECLARE_TASK(task2Handle, Task2, stack2,
STACK2SIZ)
RK_DECLARE_DYNAMIC_TASK(task3Handle, Task3)
RK_DECLARE_DYNAMIC_TASK(task4Handle, Task4)
RK_DECLARE_DYNAMIC_STACK_POOL(dynamicTaskMem, stackPool,
N_DYN_TASKS, DYNSTACKSIZ)
static RK_DYNAMIC_TASK_ATTR task3Attr =
{
.taskFunc = Task3,
.argsPtr = RK_NO_ARGS,
.taskName = "Task3",
.priority = 1U,
.preempt = RK_PREEMPT,
.stackMemPtr = &dynamicTaskMem
};
static RK_DYNAMIC_TASK_ATTR task4Attr =
{
.taskFunc = Task4,
.argsPtr = RK_NO_ARGS,
.taskName = "Task4",
.priority = 1U,
.preempt = RK_PREEMPT,
.stackMemPtr = &dynamicTaskMem
};
VOID kApplicationInit(VOID)
{
/* Initialise dynamic task memory partition */
RK_ERR err = kMemPartitionInit(&dynamicTaskMem,
stackPool,
sizeof(stackPool[0]),
N_DYN_TASKS);
K_ASSERT(err == RK_ERR_SUCCESS);
/*initialise static tasks */
err = kTaskInit(&task1Handle,
Task1,
RK_NO_ARGS,
"Task1",
stack1,
STACK1SIZ,
1U,
RK_PREEMPT);
K_ASSERT(err == RK_ERR_SUCCESS);
/* note task2 has lower priority than 1, 3 and 4 */
err = kTaskInit(&task2Handle,
Task2,
RK_NO_ARGS,
"Task2",
stack2,
STACK2SIZ,
2U,
RK_PREEMPT);
K_ASSERT(err == RK_ERR_SUCCESS);
}
VOID Task1(VOID* args)
{
RK_UNUSEARGS
ULONG count = 0UL;
while (1)
{
printf("COUNT1: %lu [TASK1] running\r\n", count);
count++;
/* Task1 spawns Task3 after 10 iterations */
if (count == 10)
{
printf("COUNT1: %lu !!!! [TASK1] spawning Task3\r\n", count);
RK_ERR err = kTaskSpawn(&task3Attr, &task3Handle);
K_ASSERT(err == RK_ERR_SUCCESS);
}
kSleep(10U);
}
}
VOID Task2(VOID* args)
{
RK_UNUSEARGS
ULONG count = 0UL;
/* Task2 spawns Task4 right off q*/
printf("COUNT2: !!!! %lu [TASK2] spawning Task4\r\n", count);
RK_ERR err = kTaskSpawn(&task4Attr, &task4Handle);
K_ASSERT(err == RK_ERR_SUCCESS);
while (1)
{
printf("COUNT2: %lu [TASK2] running\r\n", count);
count++;
kSleep(10U);
}
}
VOID Task3(VOID* args)
{
RK_UNUSEARGS
ULONG count = 0UL;
while (1)
{
/* Task3 never terminates */
printf("COUNT3: %lu [TASK3] running\r\n", count);
count++;
kSleep(10U);
}
}
VOID Task4(VOID* args)
{
RK_UNUSEARGS
ULONG count = 0UL;
while (1)
{
count++;
printf("COUNT4: %lu [TASK4] running\r\n", count);
if (count == 20)
{
/* Task4 terminates itself after 20 iterations */
printf("COUNT4: %lu !!!! [TASK4] terminating self\r\n", count);
RK_ERR err = kTaskTerminateSelf();
K_ASSERT(err == RK_ERR_SUCCESS);
}
kSleep(10U);
}
}COUNT1: 0 [TASK1] running
COUNT2: !!!! 0 [TASK2] spawning Task4
COUNT4: 1 [TASK4] running
.
/* task3 is spawned later */
COUNT1: 10 !!!! [TASK1] spawning Task3
COUNT3: 0 [TASK3] running
COUNT2: 9 [TASK2] running
COUNT3: 1 [TASK3] running
COUNT1: 10 [TASK1] running
.
COUNT3: 9 [TASK3] running
COUNT1: 18 [TASK1] running
COUNT4: 19 [TASK4] running
COUNT2: 18 [TASK2] running
COUNT4: 20 [TASK4] running
COUNT4: 20 !!!! [TASK4] terminating self
.
/* from now on, only 1, 2, 3 keep going */
COUNT1: 19 [TASK1] running
COUNT3: 10 [TASK3] running
COUNT2: 19 [TASK2] running
.
|
9. Inter-Task Communication: Signals and Messages
Inter-Task Communication (ITC) refers to the mechanisms that enable tasks to coordinate/cooperate/synchronise by means of sending or receiving information that falls into two logical categories: Signals or Messages.
Again:
-
Signals: A Signal is either present or absent, most often than not, signals are registered as a token — that either accumulates or not (cap at 1). The meaning is implicit.
-
Messages: A Message is a means of coordinating and exchanging information altogether. Different from a Signal, each message may convey a different information.
9.1. Semaphores
| Semaphore Control Block |
|---|
Counter (Unsigned Integer) |
Maximum Value |
Waiting Queue |
Semaphores are public kernel objects for signalling and waiting on countable events. Any task can wait or signal a semaphore.
A semaphore S is a nonnegative integer variable, apart from the operations it is subjected to. S is initialised to a nonnegative value. The two operations, called P and V, are defined as follows:
P(S): if S > 0 then S := S-1, else the process is suspended until S > 0.
V(S): if there are processes waiting, then one of them is resumed; else S := S+1.
(Dijkstra, 1968)
V() in RK0 semaphores maps to post() and P() to pend().
9.1.1. Counting Semaphore and Binary Semaphores
The typical use case for semaphores is as a "credit tracker": use pend() to consume a credit and post() to return a credit (for example, free slots in a queue). These are Counting Semaphores.
A Binary Semaphore is a counting semaphore with maximum value 1: the state is either available or unavailable. They are often used for task-to-task or ISR-to-task synchronisation, and sometimes for mutual exclusion (with caveats discussed later).
A semaphore that is intended never to saturate can use a maximum value of UINT32_MAX.
9.1.2. Semaphores in RK0
To initialise a semaphore in RK0, provide two values: initial count and maximum count. When the counter is at maximum, post() does not increment it and returns RK_ERR_SEMA_FULL.
This return code is not negative, so it is not an handled as an error, but normally for a counting semaphore if you established an upper bound and is signalling more times than that, it means credits are not being consumed.
query() inspects current state: non-negative means current count; negative means number of tasks waiting.
The operation for flushing a semaphore (waking all pending tasks) was deprecated on V0.16.0. Now only
Sleep Queues have wake/flush().
9.1.2.1. Usage example: Mailbox
In embedded software, normally a Mailbox is a shared buffer with controlled access for depositing and retrieving a single item.
A successful send() will make the mailbox FULL. A recv() that consumes the message will make it EMPTY.
If both send() and recv() are meant to be blocking, a simple Mailbox can be built around shared memory and two binary semaphores.
/* pseudo-code: mailbox with rendezvous */
ULONG mailbox = 0; /* just a shared variable */
/* Binary semaphores initial value */
/* mailbox is initially empty (room=1, data=0) */
BIN_SEMA data = 0;
BIN_SEMA room = 1;
/* after sending, mailbox is full */
VOID sendMail(ULONG const inData)
{
Pend(&room); /* if 0 block, else room=0 */
/* assuming there is no risk of preemption/interrupt
that will touch the shared variable */
mailbox = inData; /* fill it up */
Post(&data); /* if 0 wake any receiver; else data=1 */
}
/* after receiving, mailbox is empty */
VOID recvMail(ULONG * const recvPtr)
{
Pend(&data); /* if 0 block, else data=0 */
*recvPtr = mailbox; /* consume data */
Post(&room); /* if 0 wake any senders; else room=1 */
}9.1.2.2. Usage Example: Producer-consumer general solution
A general solution for a producer-consumer relationship, considers a buffer with K items, K>=1 slots, uses Semaphores both as credit-trackers and mutual exclusion mechanisms.
When items are inserted and removed from a memory region, whose capacity is bounded to K items, the following invariant holds:
0 < (Number of Inserted Items) – (Number of Extracted Items) < K.
Semaphores are used as follows:
-
A semaphore with
Ktokens to track free slots, preventing producers from proceeding when there are no free slots. -
Another semaphore, with
Ktokens, for the number of items, not allowing consumers to proceed if there are no items. -
A 1-token semaphore so only one task manipulates the buffer at a time.
/* a ring buffer of items */
#define BUFSIZ (K)
static ITEM_t buf[BUFSIZ]={0};
static UINT getIdx = 0U;
static UINT putIdx = 0U;
/* getIdx==putIdx==0 could either mean FULL or EMPTY for a regular
circular buffer with wrap-around. When using semaphores they define the state.
*/
RK_SEMAPHORE itemSema; /* counting semaphore for number of items in the buffer */
RK_SEMAPHORE slotSema; /* counting semaphore for number of free slots in the buffer */
RK_SEMAPHORE acquireSema; /* binary semaphore for mutual exclusion (it is not a LOCK, there is no ownership notion) */
VOID kApplicationInit(VOID)
{
/*buffer is initialised empty */
kSemaphoreInit
( &itemSema,
0, /* no item */
K /*max items */
);
kSemaphoreInit
( &slotSema,
K, /* K free slots */
K /* max slots */
);
/* and free */
kSemaphoreInit
( &acquireSema,
1, /* free to access */
1 /* 1 max task allowed */
);
VOID PutItem(ITEM_t const * const insertItemPtr)
{
RK_ERR err = -1;
/* wait for room */
err = kSemaphorePend(&slotSema, RK_WAIT_FOREVER);
K_ASSERT(err == RK_ERR_SUCCESS);
/* wait for availability */
err = kSemaphorePend(&acquireSema, RK_WAIT_FOREVER);
K_ASSERT(err == RK_ERR_SUCCESS);
buf[putIdx] = *insertItemPtr;
putIdx += 1U;
putIdx %= BUFSIZ;
/* signal availability */
err = kSemaphorePost(&acquireSema);
K_ASSERT(err == RK_ERR_SUCCESS);
/* signal item */
err = kSemaphorePost(&itemSema);
K_ASSERT(err == RK_ERR_SUCCESS);
}
VOID GetItem(ITEM_t * const extractItemPtr)
{
RK_ERR err = -1;
/* wait for an item */
err = kSemaphorePend(&itemSema, RK_WAIT_FOREVER);
K_ASSERT(err == RK_ERR_SUCCESS);
/* wait for availability */
err = kSemaphorePend(&acquireSema, RK_WAIT_FOREVER);
K_ASSERT(err == RK_ERR_SUCCESS);
*extractItemPtr = buf[getIdx];
getIdx += 1U;
getIdx %= BUFSIZ;
/* signal availability */
err = kSemaphorePost(&acquireSema);
K_ASSERT(err == RK_ERR_SUCCESS);
/* signal room */
err = kSemaphorePost(&slotSema);
K_ASSERT(err == RK_ERR_SUCCESS);
}The solution above has Put() and Get() as blocking methods.
If the producer and the consumer run at different rates, eventually, they will synchronise to the lowest rate.
The numbers below are from a run with a buffer of 32 items (integers being incremented are the produced data).
The producer is twice faster than the consumer. Initially at every 2 insertions there is a single remove.
Put 59 <-
Put 60 <-
------
Got 30 ->
------
Put 61 <-
Put 62 <-
------
Got 31 ->
------
Put 63 <-
Put 64 <-
--------
Got 32 | ->
Put 65 . <-
<x>[Full Queue, Producer blocks]
Got 33 | -> [Consumer unblocks producer...]
Put 66 . <-
<x>[Full Queue]
Got 34 | -> [Consumer unblocks producer...]
Put 67 . <-
<x>[Full Queue]| When two tasks at different rates insert and remove from the same buffer, and both operations are blocking, eventually they will run at the pace of the lowest task. |
9.2. Sleep Queue (Condition Queue)
| Sleep Queue Control Block |
|---|
Task Waiting Queue |
Sleep Queues are the crudest synchronisation primitive in RK0, because it is stateless (there is no token).
Unlike Semaphores, a wait() unconditionally switches the caller to a SLEEPING state until the queue is signalled (or broadcasted).
Sleep Queue names usually reflect the condition they will be waiting for, or the action they will execute once signalled.
A signal() wakes the higher priority task. Different from Semaphores, Sleep Queues support waking
several tasks at once via wake(n) — a broadcast.
A wake(n) wakes at most n tasks if any. This provides some control over the the always questionable overhead of broadcast signals. If
n=0 it will flush.
If broadcasting from an ISR, the operation is deferred for the PostProcessingTask, to keep the ISR short.
| A broadcast harms overall responsiveness. Avoid flushing from interrupts, if doing keep it minimal. |
A query() returns the number of waiting tasks.
Another particular operation for sleep queues is the suspend(): it moves a READY task to a sleep queue. This is done to prevent a task from being scheduled. Tasks states other than READY are not affected by this operation.
Please note that using this operation is literally poking the scheduler, so it is not something one expect to be using.
ready() reverts suspend().
Importantly a Sleep Queue is not a Condition Variable as we know it (e.g, from Pthreads) — but it is a building block for coordination mechanisms.
9.3. Mutex Lock
| Mutex Control Block |
|---|
Locked State (Boolean) |
Owner |
Protocol Flag ( |
Waiting Queue |
Mutex Node (list node within the owner TCB) |
Some regions are critical and must not be executed by more than one task at once. Acquiring (lock()) a mutex before entering and releasing (unlock()) after leaving makes the region mutually exclusive.
A Mutex is a binary semaphore with ownership: once a task locks a mutex only that task can unlock it.
If a task tries to acquire a locked mutex, it switches to BLOCKED until the owner unlocks it. When released, the highest-priority waiter is dequeued first.
Unlike semaphores, unlocking by a non-owner is invalid and rejected.
Mutexes are only for mutual exclusion; they are not signalling primitives.
PS: RK0 mutexes are non-recursive. Re-entrant locking of the same mutex returns RK_ERR_MUTEX_REC_LOCK and is considered a fault.
9.3.1. Priority Inversion and PIP
Let TH, TM, and TL be three tasks with priority high (H), medium (M) and low (L), respectively. Say TH is dispatched and blocks on a mutex that 'TL' has acquired (i.e.: "TL is blocking TH").
If 'TM' does not need the resource, it will run and preempt 'TL'. And, by transition, 'TH'.
From now on, 'TH' has an unbounded waiting time because any task with priority higher than 'L' that does not need the resource indirectly prevents it from being unblocked — awful.
The Priority Inheritance (PI) Protocol avoids this unbounded waiting. It is characterised by an invariant, simply put:
PIP Invariant: At any instant a Task assumes the highest priority among the tasks it is blocking.
If employed on the situation described above, task TM cannot preempt TL, whose effective priority would have been raised to 'H'.
It is straightforward to reason about this when you consider the scenario of a single mutex.
When locks nest, the protocol also needs to be:
-
Transitive: if T1 blocks T2 and T2 blocks T3, the highest priority (T3) must propagate back to T1 through T2.
This is the hard part of a correct implementation: updates must preserve the invariant across changing wait chains and multiple mutexes.
|
This blog shows an even more intricate case of priority inversion handling. |
Below, a case in which locks nest:
/* Task1 has the Highest nominal priority */
/* Task2 has the Medium nominal priority */
/* Task3 has Lowest nominal priority */
/* Note Task3 starts as 1 and 2 are delayed */
RK_DECLARE_TASK(task1Handle, Task1, stack1, STACKSIZE)
RK_DECLARE_TASK(task2Handle, Task2, stack2, STACKSIZE)
RK_DECLARE_TASK(task3Handle, Task3, stack3, STACKSIZE)
RK_MUTEX mutexA;
RK_MUTEX mutexB;
VOID kApplicationInit(VOID)
{
K_ASSERT(!kTaskInit(&task1Handle, Task1, RK_NO_ARGS, "Task1", stack1, \
STACKSIZE, 1, RK_PREEMPT));
K_ASSERT(!kTaskInit(&task2Handle, Task2, RK_NO_ARGS, "Task2", stack2, \
STACKSIZE, 2, RK_PREEMPT));
K_ASSERT(!kTaskInit(&task3Handle, Task3, RK_NO_ARGS, "Task3", stack3, \
STACKSIZE, 3, RK_PREEMPT));
/* mutexes initialised with priority inheritance enabled */
kMutexInit(&mutexA, RK_INHERIT);
kMutexInit(&mutexB, RK_INHERIT);
}
VOID Task3(VOID *args)
{
RK_UNUSEARGS
while (1)
{
printf("@ %lums: [TL] Attempting to LOCK 'A' | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kMutexLock(&mutexA, RK_WAIT_FOREVER);
printf("@ %lums: [TL] LOCKED 'A' (in CS) | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kDelay(60); /* <-- important */
printf("@%lums: [TL] About to UNLOCK 'A' | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kMutexUnlock(&mutexA);
printf("--->");
printf("@%lums: [TL] Exit CS | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kSleep(4);
}
}
VOID Task2(VOID *args)
{
RK_UNUSEARGS
while (1)
{
kSleep(5);
printf("@%lums: [TM] Attempting to LOCK 'B' | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kMutexLock(&mutexB, RK_WAIT_FOREVER);
printf("@%lums: [TM] LOCKED 'B', now trying to LOCK 'A' | Eff: %d | Nom: %d\r\n",
kTickGet(), runPtr->priority, runPtr->prioNominal);
kMutexLock(&mutexA, RK_WAIT_FOREVER);
printf("@%lums: [TM] LOCKED 'A' (in CS) | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kMutexUnlock(&mutexA);
printf("@%lums: [TM] UNLOCKING 'B' | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kMutexUnlock(&mutexB);
printf("--->");
printf("@%lums: [TM] Exit CS | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
}
}
VOID Task1(VOID *args)
{
RK_UNUSEARGS
while (1)
{
kSleep(2);
printf("@%lums: [TH] Attempting to LOCK 'B'| Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kMutexLock(&mutexB, RK_WAIT_FOREVER);
printf("@%lums: [TH] LOCKED 'B' (in CS) | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
kMutexUnlock(&mutexB);
printf("--->");
printf("@%lums: [TH] Exit CS | Eff: %d | Nom: %d\r\n", kTickGet(),
runPtr->priority, runPtr->prioNominal);
}
}Result and comments:
>>>> TL locks 'A'. Higher priority tasks are sleeping. <<<< @ 14720ms: [TL] Attempting to LOCK 'A' | Eff: 3 | Nom: 3 @ 14720ms: [TL] LOCKED 'A' (in CS) | Eff: 3 | Nom: 3 @14721ms: [TM] Attempting to LOCK 'B' | Eff: 2 | Nom: 2 >>>> TM acquires 'B' and is blocked by TL on 'A'. TL inherits TM's priority. <<<< @14721ms: [TM] LOCKED 'B', now trying to LOCK 'A' | Eff: 2 | Nom: 2 >>>> TH will blocked by TM on 'B': <<<< @14722ms: [TH] Attempting to LOCK 'B'| Eff: 1 | Nom: 1 >>>> TM inherits TH's priority. TL inherits TH's priority via TM. <<<< @14780ms: [TL] About to UNLOCK 'A' | Eff: 1 | Nom: 3 >>>> Upon unlocking 'A', TL is preempted by TM. It means TL's priority has been restored, as it is no longer blocking a higher priority task. <<<< >>>> Now TM acquires 'A' <<<< @14780ms: [TM] LOCKED 'A' (in CS) | Eff: 1 | Nom: 2 >>>> After releasing 'A', but before releasing 'B', TM's priority is still '1', as it is blocking TH while holding 'B'. <<<< @14780ms: [TM] UNLOCKING 'B' | Eff: 1 | Nom: 2 >>>> Upon unlocking 'B' TM is preempted by TH. (TM's priority has been restored.) <<<< @14780ms: [TH] LOCKED 'B' (in CS) | Eff: 1 | Nom: 1 >>> RESULT: even though priority inversion was enforced, tasks leave the nested lock ordered by their nominal priority. <<< --->@14780ms: [TH] Exit CS | Eff: 1 | Nom: 1 --->@14780ms: [TM] Exit CS | Eff: 2 | Nom: 2 --->@14780ms: [TL] Exit CS | Eff: 3 | Nom: 3
Importantly, the worst-case time is bounded by the time the lowest priority task holds a lock (60 ms in the example: 14720ms → 14780ms).
As for each priority update we check each waiting queue for each mutex a task owns, t he time-complexity is linear O(owner*mutex). But, typically no task ever holds more than a few mutexes. Yet, one should not be encouraged to nest locks if not needed.
9.3.2. Mutexes vs Binary Semaphores
There is (or used to be) a lot of fuss about whether binary semaphores are appropriate to use as locks. As a practical guideline, if all tasks sharing the resource have the same priority, using a binary semaphore can be appropriate — because a binary semaphore is considerably faster. It all depends on the case.
The drawback is the lack of ownership: any task can accidentally release the resource. On a large codebase, this can become a real problem. Nonetheless, this is a problem for semaphores in general.
For tasks with different priorities, binary semaphores should never be considered for mutual exclusion unless priority inversion is not a problem (how?).
Counting semaphores initialised as 1 is too risky. Besides the priority inversion, if the count ever increases above 1, mutual exclusion is lost, and multiple tasks can enter the critical section at once.
9.4. Task Event Register
| Within Task Control Block |
|---|
Event Register Value ( |
Required Events ( |
Satisfy Condition (options: |
The task’s Event Register is like a private array of 32 binary semaphores.
Each Task Control Block stores a 32-bit event register (an ULONG, typedefed as RK_EVENT_FLAG).
A bit set within a task’s event register means another task or ISR has signalled an occurrence. The meaning is application-defined.
As they are not a public kernel object, only the task itself wait for a combination of binary tokens on its Event Register. Any other task can set.
-
Operations:
-
A
set(receiverTask, inputFlags)operation is always aORofinputFlagsover the current value stored on the Event Register. Thus, it is only able to set new tokens, not to clear. -
A
get(requiredFlags, ALL/ANY, storePtr, timeout)will check ifALLorANYof therequiredFlagsare set. If so, the required flags are cleared and the task returns successful. If not, the task either blocks or returns immediately with a positive return code value. In the case conditions are satisfied, ifstorePtris notNULLthe values on the event register are copyied to the indicated address before being cleared so the task can inspect which flags were set — specially useful when usingANY. -
An
eventClear(taskHandle, mask)will clear the bits marked as 1 inmask. -
An
eventQuery(taskHandle, storeAddr)will inspect the current status of the event register on a task. In both operations iftaskHandleisNULL, the API considers the caller as the target task handle. -
For convenience there are macros encoding the bit position as a 32-bit number. e.g.,
RK_EVENT_1equals0x00000001, …,RK_EVENT_6equals0x00000020;RK_EVENT_32equals0x80000000andRK_ALL_EVENTSequals0xFFFFFFFF.
-
9.5. Scheduler Lock
Often, we need a task to perform operations without being preempted. A mutex serialises access to a code region but does not prevent a task from being preempted while operating on data. Depending on the case, this can lead to inconsistent data state.
An aggressive way is to disable interrupts globally. For kernel services often it is the only way to keep data integrity. On the higher level it is feasible for very short operations and/or when you need to protect data from interrupts altogether.
A less aggressive approach is to make the task non-preemptible with kSchLock() before entering the critical region and kSchUnlock() when leaving. This way, interrupts are still being sensed, and even higher-priority tasks might switch to a ready state, but the running thread will not be preempted.
The priority inversion it potentially causes is bounded. If a higher-priority task is readied while the scheduler is locked, the context switch happens immediately after unlocking.
Note that for locking/unlocking the scheduler the global interrupts will be disabled for the time to increment/decrement a counter, therefore, if your atomic operation is as short as that (3 to 4 cycles), disabling/enabling global interrupts is a better alternative.
To add to the discussion, when two threads need to access the same data to 'read-modify-write', a lock-free mechanism is the LDREX/STREX operations of ARMv7M (or more generally C11 atomics). They do not avoid preemptions, and particularly in ARMv7m, if the data is touched by an ISR before the store-exclusive concludes, the ownership is lost. Typically used for multi-core spin-locking.
9.6. Monitors and the Condition Variable Model
Task Events and semaphores work by atomically updating state and testing predicates that control execution flow (for example, pend on a semaphore with count 0 blocks the caller).
A critical region guarded by a lock is either free or taken. What if we need to wait on a richer condition? We express this condition on a shared variable and check for it within a critical region.
If the condition is not satisfied, we need to block until it is, but we need to release the lock before sleeping, otherwise, the task that could change the condition and wake us up would be blocked by the lock we are holding.
To prevent that, the sleeping task releases the lock and goes to sleep atomically (from the task preemption perspective) — kSchLock()/kSchUnlock() are particularly suitable here.
If we create a data structure with state variables, the Mutex lock, and the Sleep Queues associated to each condition, plus a set of operations acting over this structure, we have an ADT. This ADT is called a Monitor.
9.6.1. Monitor Invariants
A Monitor needs to respect two invariants:
-
a single task can be active within a monitor;
-
only the active task within a monitor can check or change its state.
Given the above invariants, how to keep the a single active task within a monitor if the active task is the one who is waking other tasks?
This comes down to the Signalling Discipline.
9.6.2. Signalling Discipline
At any moment a single task can be active within a monitor. When the sleeping task is signalled, there are 3 common disciplines to follow: signal-and-leave (Hansen), signal-and-wait (Hoare) or signal-and-continue (Mesa).
Arguably, the most common is signal-and-continue — rather than leaving or suspending itself the active task might continue within the monitor. That is possible if the active task holds a lock the waking task needs to acquire to enter. Upon leaving, the active task must release the lock.
The major implication is that by the time the woken task enters the monitor, the condition it was waiting for might no longer be true. It sounds odd because a Monitor is about encapsulating a conditional critical region so no outsiders change its state. But, either a flush, a bad design — or a preemption anomaly — can violate that somehow.
Mesa Monitor has a typical test-loop pattern:
--- snippet ---
while (condition is FALSE)
{
/*unlock-wait sequence:*/
ATOMIC_BEGIN
unlock(mutex); /*the atomic unlock-sleep we referred earlier */
sleep(condition)
ATOMIC_END
lock(mutex);
/* when waking, the while clause is tested again */
}
--- snippet ---9.6.3. Condition Variable Model
The Condition Variable Model allows a task to wait within a monitor-construct and if active, operate using signal(), wait() and broadcast() respecting the monitor invariant.
Sleep Queues are like the seminal Condition Variable as introduced by Hoare:
Note that a condition "variable" is neither true nor false; indeed, it does not have any stored value accessible to the program. In practice, a condition variable will be represented by an (initially empty) queue of processes which are currently waiting on the condition; but this queue is invisible both to waiters and signallers. This design of the condition variable has been deliberately kept as primitive and rudimentary as possible (…)
(Monitors: An Operating System Structuring Concept, Hoare, 1974)
RK0 does not have a POSIX-like Condition Variable primitive. Sleep Queues are supposed to be combined with mutexes to create Monitor-like mechanisms.
There are helpers that follow the Mesa semantics (the same used in Pthreads):
-
kCondVarWait(&sleepq, &mutex, timeout) -
kCondVarSignal(&sleepq) -
kCondVarBroadcast(&sleepq)
The condWait is the real helper. When using it, a Mesa testing-loop reduces to:
while(!condition)
{
kCondVarWait(&condQueue, &monitorLock, timeout);
}Besides providing atomicity it this helper also uses timeout as the time budget for waiting on both Sleep Queue plus Monitor Lock; that is, the timeout can be seen as a timeout for a single blocking call.
If you need a monitor policy different from Mesa, you can build it from the same primitives.
kCondVarWait, kCondVarSignal, and kCondVarBroadcast are task-context APIs and cannot be called from ISRs.
|
9.6.3.1. Usage Example: Synchronisation Barrier
A given number of tasks must reach a point in the program before all can proceed, so every task calls a barrWait(&barrier) to synchronise at the barrier, waiting until the number of required tasks is met.
When a task enters the barrier and increases the counter so it meets the required number, it broadcast a signal to all tasks sleeping within the monitor.
A new round starts.
(Interestingly, a barrier solves the need for mutual coincidence, the very opposite of mutual exclusion.)
In application.c in the repo, you can find a more realistic implementation that assigns time outs and implements this pattern using both shared state and message passing paradigms.
|
/* Synchronisation Barrier */
typedef struct
{
RK_MUTEX lock;
RK_SLEEP_QUEUE allSynch;
UINT count; /* number of tasks in the barrier */
UINT round; /* increased every time all tasks synch */
UINT nRequired; /* number of tasks required */
} Barrier_t;
VOID BarrierInit(Barrier_t *const barPtr, UINT nRequired)
{
kMutexInit(&barPtr->lock, RK_INHERIT);
kSleepQueueInit(&barPtr->allSynch);
barPtr->count = 0;
barPtr->round = 0;
barPtr->nRequired = nRequired;
}
VOID BarrierWait(Barrier_t *const barPtr)
{
UINT myRound = 0;
kMutexLock(&barPtr->lock, RK_WAIT_FOREVER);
/* save round number */
myRound = barPtr->round;
/* increase count on this round */
barPtr->count++;
if (barPtr->count == barPtr->nRequired)
{
/* reset counter, inc round, broadcast to sleeping tasks */
barPtr->round++;
barPtr->count = 0;
kCondVarBroadcast(&barPtr->allSynch);
}
else
{
/* sequence: a proper wake signal might happen after inc round */
while ((UINT)(barPtr->round - myRound) == 0U)
{
RK_ERR err = kCondVarWait(&barPtr->allSynch, &barPtr->lock, RK_WAIT_FOREVER);
K_ASSERT(err==RK_ERR_SUCCESS);
}
}
kMutexUnlock(&barPtr->lock);
}
#define N_REQUIRED 3
Barrier_t syncBarrier;
VOID kApplicationInit(VOID)
{
K_ASSERT(!kTaskInit(&task1Handle, Task1, RK_NO_ARGS, "Task1", stack1, STACKSIZE, 2, RK_PREEMPT));
K_ASSERT(!kTaskInit(&task2Handle, Task2, RK_NO_ARGS, "Task2", stack2, STACKSIZE, 3, RK_PREEMPT));
K_ASSERT(!kTaskInit(&task3Handle, Task3, RK_NO_ARGS, "Task3", stack3, STACKSIZE, 1, RK_PREEMPT));
BarrierInit(&syncBarrier, N_REQUIRED);
}
VOID Task1(VOID* args)
{
RK_UNUSEARGS
while (1)
{
kPuts("Task 1 is waiting at the barrier...\r\n");
BarrierWait(&syncBarrier);
kPuts("Task 1 passed the barrier!\r\n");
kSleep(8);
}
}
VOID Task2(VOID* args)
{
RK_UNUSEARGS
while (1)
{
kPuts("Task 2 is waiting at the barrier...\r\n");
BarrierWait(&syncBarrier);
kPuts("Task 2 passed the barrier!\r\n");
kSleep(5);
}
}
VOID Task3(VOID* args)
{
RK_UNUSEARGS
while (1)
{
kPuts("Task 3 is waiting at the barrier...\r\n");
BarrierWait(&syncBarrier);
kPuts("Task 3 passed the barrier!\r\n");
kSleep(3);
}
}
Note the sequence tasks run before entering the monitor and the sequence they leave. They leave ordered by priority when the flush happens because the mutexes enforces that queue discipline. The priority of Task2 is lower than Task1, although its request rate is higher (5 vs 8 ticks delay), so it leaves first.
9.6.3.2. Usage Example: Readers Writers Lock
Several readers and writers share a piece of memory. Readers can concurrently access the memory to read; a single writer is allowed (otherwise, data would be corrupted).
When a writer finishes, it checks for any readers waiting. If there is, the writer flushes the readers waiting queue. If not, it wakes a single writer, if any. When the last reader finishes, it signals a writer.
Every read or write operation begins with an acquire and finishes with a release.
PS: This RWLock implementation has a reader-preference policy, as when a writer finishes, it flushes sleeping readers. When the last reader finishes, it will signal writer waiting queue.
/* RW-Lock */
/* a single writer is allowed if there are no readers */
/* several readers are allowed if there is no writer*/
typedef struct
{
RK_MUTEX lock;
RK_SLEEP_QUEUE writersGo;
RK_SLEEP_QUEUE readersGo;
INT rwCount; /* number of active readers if > 0 */
/* active writer if -1 */
}RwLock_t;
VOID RwLockInit(RwLock_t *const rwLockPtr)
{
kMutexInit(&rwLockPtr->lock, RK_INHERIT);
kSleepQueueInit(&rwLockPtr->writersGo);
kSleepQueueInit(&rwLockPtr->readersGo);
rwLockPtr->rwCount = 0;
}
/* A writer can acquire if rwCount = 0 */
/* An active writer is indicated by rwCount = -1; */
VOID RwLockAcquireWrite(RwLock_t *const rwLockPtr)
{
kMutexLock(&rwLockPtr->lock, RK_WAIT_FOREVER);
/* if different than 0, there are either writers or readers */
/* sleep to be signalled */
while (rwLockPtr->rwCount != 0)
{
kCondVarWait(&rwLockPtr->writersGo, &rwLockPtr->lock, RK_WAIT_FOREVER);
/* mutex is locked when waking up*/
}
/* woke here, set an active writer */
rwLockPtr->rwCount = -1;
kMutexUnlock(&rwLockPtr->lock);
}
/* a writer releases, waking up all waiting readers, if any */
/* if there are no readers, a writer can get in */
VOID RwLockReleaseWrite(RwLock_t *const rwLockPtr)
{
kMutexLock(&rwLockPtr->lock, RK_WAIT_FOREVER);
rwLockPtr->rwCount = 0; /* indicate no writers*/
/* if there are waiting readers, flush */
ULONG nWaitingReaders=0;
kSleepQueueQuery(&rwLockPtr->readersGo, &nWaitingReaders);
if (nWaitingReaders > 0)
{
/* condVarBroadcast is just an alias for an event flush */
kCondVarBroadcast(&rwLockPtr->readersGo);
}
else
{
/* wake up a single writer if any */
kCondVarSignal(&rwLockPtr->writersGo);
}
kMutexUnlock(&rwLockPtr->lock);
}
/* a reader can acquire if there are no writers */
VOID RwLockAcquireRead(RwLock_t *const rwLockPtr)
{
kMutexLock(&rwLockPtr->lock, RK_WAIT_FOREVER);
/* if there is an active writer, sleep */
while (rwLockPtr->rwCount < 0)
{
kCondVarWait(&rwLockPtr->readersGo, &rwLockPtr->lock, RK_WAIT_FOREVER);
/* mutex is locked when waking up*/
}
/* increase rwCount, so its > 0, indicating readers */
rwLockPtr->rwCount ++;
kMutexUnlock(&rwLockPtr->lock);
}
/* a reader releases and wakes a single writer */
/* if it is the last reader */
VOID RwLockReleaseRead(RwLock_t *const rwLockPtr)
{
kMutexLock(&rwLockPtr->lock, RK_WAIT_FOREVER);
rwLockPtr->rwCount --;
if (rwLockPtr->rwCount == 0)
{
kCondVarSignal(&rwLockPtr->writersGo);
}
kMutexUnlock(&rwLockPtr->lock);
}In the image below, 4 tasks — a fast writer (Task 1), a slow writer (Task 4) and two readers (Task3 is faster than Task2) — reading from and writing to a shared UINT variable:

9.7. Context-switching cost, blocking and priority assignment
The detailed exposition of Monitor-like constructions might lead the reader to understand we consider it a 'silver-bullet'. Not at all. Indeed, Monitor constructs and the Mesa semantics particularly can impose heavy context switching activity and they are a pattern optimised for the general-case. For general-purpose operating systems this is gold. We care about responsiveness, then we need to look at this pattern with a different perspective. Golden rule:
Avoid triggering context-switches for no useful work.
A task signalling a higher priority task’s sleep queue is saying — 'the condition you need to run was satisfied'. Once the task is ready, the scheduler will dispatch it. It can’t see beyond that.
If a lower priority task readies a higher priority task while holding a lock the signalled task needs, it is explictly causing a priority inversion.
Mutexes in RK0 will bound priority inversion, because kernel mechanisms are supposed handle the worst cases — the application could not avoid. Whether this will become problem or not, depends on the case. As it is expensive, Priority inversions are not to be injected on the code — this is an anti-pattern.
With that in mind, do not take the (functional, but generic) patterns here as optimal recipes without considering the priority of the tasks that are using monitor-like schemes, and your application demands. The run-time model is already simple to aid on reasoning.
Finally, this discussion applies to any blocking inter-task comunication, including message-passing mechanisms exposed on the next-section.
9.8. Message Queue
| Message Queue Control Block |
|---|
Owner Task |
Buffer Address |
Message Size |
Number of Mesages |
Write Position |
Read Position |
Notify callback |
Waiting queue |
Message Queues (RK_MESG_QUEUE) are public message-passing kernel objects with optional ownership. When queues have an owner task (a single task allowed to reeive) we regard them as PORTS; it is not another kernel object . The Message Queue API is aware of ownership and handles it.
Each message queue has a backing storage holding N messages of a fixed-size S.
We say that C = N x S [Words] is the queue capacity.
Message Queues transmit by copy. Sending and receiving are either blocking or non-blocking.
Each message queue will preserve discrete message history up to queue capacity when the producer uses blocking semantics.
If the producer occasionally outruns the consumer, a message queue amortises bursts or consumer lateness without missing data. A faster consumer, on the other hand, will eventually block on an empty queue; it does not drop messages. Drops occur when the producer outruns the consumer and uses non-blocking sends.
This was demonstrated using semaphores on the producer-consumer problem.
In practice, buffering gives time-data correlation only within queue capacity. Over long runs, effective throughput is bounded by the slowest stage, so either the producer blocks on a full queue — what we call backpresssure — or the system accepts that some data will be missed.
Rule of thumb: long-term throughput equals the slowest stage; buffers only absorb short-term mismatch and jitter.
9.8.1. Size of a Message
Each declared queue has a fixed message-size at initialisation, and can assume, 1, 2, 4 or 8 WORDs (4, 8, 16, 32 BYTEs). This constraint is intentional. Word-aligned copies are faster, predictable and safer for type casting.
(A word-aligned single copy will take ~5 cycles in Cortex-M3/4/7, and ~6 cycles on Cortex-M0/M0+.)
9.8.2. Ownership (Ports)
If a Message Queue is assigned to a single owner it is a Port. Note Ports are not a kernel object, they are still message queues; the message queue API handles ownership itself (there is a wrapper API, kPort* that has as target object an owner task of a message queue, for readability).
When a queue has an owner assigned the operations will enforce:
-
Only the owner task can receive from that message queue.
-
Priority inheritance is applied when a higher priority task blocks on a queue owned by a lower priority one, to diminish priority inversion. Note that it is still an undesirable situation; there is no reasonable 'priority-inversion as a design choice'.
When a queue binds to a task, main side-effect is diminishing any backpressure if the a higher priority sender blocks on a lower priority Port that buffer is full.
If the user need is enforcing a single receiver and the priority boosting side-effect is undesirable, do not use a Port: just enforce the single receiver on the application code.
9.8.3. Single-message queues (Mailboxes)
A single-message queue, we regard as a Mailbox, can assume the same semantics of a multiple-message queue, besides it is able to overwrite the current message — what is not possible for queues with depth > 1.
The method sendovw() works only on single-message queues.
In this case, a 1:N communication, last-message, can be implemented, if the receivers use a peek(), a non-consuming read operation (mailbox is kept full). If the access is not coordinated data integrity often turns out to be an issue.
Note that a 1:N communication with last-message, and non-blocking send/recv has a dedicated service (the MRM) since it is a straight fit for servo-control loops.
9.8.4. Send to Front (Jam)
A normal send() deposits the message on queue’s tail. A jam() deposits the message on the queue’s head. For mailboxes a jam() is meaningless.
9.8.5. Notify callback
A callback can be registered for to be trigerred when a queue sends a message successfuly. This is a means of notification. This callback must be short, non-blocking, and normally will be a signalling a semaphore or a setting an event on a task.
9.8.6. Usage Examples
9.8.6.1. Mail Queue pattern
A mail queue is a very useful pattern for message-passing.
It is done by combining a Memory Partition and 1-word-size message-queue, with a N>1.
Sender allocates, receiver frees the partition. This keep integrity and low overhead as the copy from sender to queue and queue to receiver is reduced to 1-word.
Below, snippets of the Application Logger facility that uses this pattern.
/* Application Logger pattern */
/* standard log structure */
struct log
{
RK_TICK t; /* timestamp */
CHAR s[LOGLEN]; /*formatted string */
UINT level; /* level 0=message, 1=fault */
} K_ALIGN(4);
typedef struct log Log_t;
/* logger mem allocator + mem pool */
static RK_MEM_PARTITION qMem;
static Log_t logBufPool[LOGPOOLSIZ] K_ALIGN(4);
/* backing buffer for the logger queue */
/* (messages are 1-word-size, number equals the pool) */
RK_DECLARE_MESG_QUEUE_BUF(logQBuf, VOID *, LOGPOOLSIZ)
/* logger mail queue */
static RK_MESG_QUEUE logQ;
/* a sender will allocate a buffer write the log
message and enqueue on the mail queue, not-blocking
if the queue is full it returns the buffer immediately
if the memory pool is empty it drops the operation */
```c
/* excerpt of logPost(...) */
VOID logPost(/*formatted string */)
---snip---
Log_t *logPtr = (Log_t*)kMemPartitionAlloc(&qMem);
RK_BARRIER
if (logPtr) /* available buffer */
{
< fill the buffer >
/* use task name (port owner) */
if (kMesgSend(logTaskHandle, &p, RK_NO_WAIT) != RK_ERR_SUCCESS)
{
/* queue is full, deallocate buf */
RK_ERR err = kMemPartitionFree(&qMem, &p);
K_ASSERT(err==RK_ERR_SUCCESS);
}
}
---snip---
/* excerpt of the logger task */
static VOID LoggerTask(VOID *args)
{
RK_UNUSEARGS
while (1)
{
VOID *recvPtr = NULL;
/* drain the queue: keep receiving while successful */
while (kMesgRecv(&recvPtr, RK_WAIT_FOREVER) == RK_ERR_SUCCESS)
{
< print buffer contents >
/* deallocate */
RK_ERR err = kMemPartitionFree(&qMem, recvPtr);
K_ASSERT(err == RK_ERR_SUCCESS);
}
}
}This is one of the many ways of using the Mail Queue pattern.
The entire implementation can be seen at app\logger.c.
9.8.6.2. Queue Select using Notify Callback
A task is receiving from many queues and need to know which one has been able to complete.
The notifyCbk(queue*) is executed every time a send is successful.
In this case it is using an Event Signal to a task.
The Signals Flag indicate the queue number - as a contract - of which queue has completed sends.
Note that as sends may coalesce, while a flag caps at 1, the consumer will drain each queue until it is empty, or it is preempted.
There are many options here; a bi-lateral synchronisation could be employed; a counting semaphore could be used so queues are
read after a threshold value, etc.
/* Many-to-1 queue channels */
/* Consumer Select queue based on its event
flags, that a succesfull send triggers */
#define LOG_PRIORITY 4 /* keep logger as lowest-priority user task */
#define STACKSIZE 256
#define NQUEUES 3 /* number of queues */
#define QSIZ 8 /* depth of each queue */
#define Q0_FLAG RK_EVENT_1 // (1<<0)
#define Q1_FLAG RK_EVENT_2 // (1<<1)
#define Q2_FLAG RK_EVENT_3 // (1<<2)
#define QFLAGS (ULONG)(Q0_FLAG | Q1_FLAG | Q2_FLAG)
typedef struct
{
RK_TASK_HANDLE producer;
UINT payload;
} MESG_t;
/* Succesful Send callbacks */
/* each callback follows this pattern */
static inline
VOID sendNotify0(RK_MESG_QUEUE *qPtr)
{
(VOID)qPtr;
kTaskEventSet(consumerHandle, Q0_FLAG);
/* Q1 flag for queue1 and so forth */
}
/* each callback in installed using kMesgQueueInstallSendCbk
on kApplicationInit() */
/* helper to send */
static inline
VOID enqueueSample(RK_MESG_QUEUE *qPtr UINT payload)
{
MESG_t mesg = {
.payload = payload,
.producer = RK_RUNNING_HANDLE,
};
RK_ERR err = kMesgQueueSend(qPtr, &mesg, RK_WAIT_FOREVER);
K_ASSERT(err == RK_ERR_SUCCESS);
}
VOID Prod0Task(VOID *args)
{
RK_UNUSEARGS
UINT seq = 0U;
while (1)
{
enqueueSample(&queues[0], seq++);
kSleepRelease(25); /* fast producer */
}
}
VOID Prod1Task(VOID *args)
{
UINT seq = 0U;
RK_UNUSEARGS
while (1)
{
enqueueSample(&queues[1], seq++);
/* every fourth sample, also tickle the third queue */
if ((seq & 0x3U) == 0U)
{
enqueueSample(&queues[2], seq);
}
kSleepRelease(60);
}
}
/* Consumer listens on all queues, selecting those on its signal flags. */
VOID ConsumerTask(VOID *args)
{
RK_UNUSEARGS
MESG_t recv = {0};
ULONG flags = 0UL;
while (1)
{
flags = 0UL;
kTaskEventGet(QFLAGS, RK_EVENT_FLAGS_ANY, &flags,
RK_WAIT_FOREVER);
for (UINT i = 0; i < NQUEUES; ++i)
{
if (flags & (1UL << i))
{
while (kMesgQueueRecv(&queues[i], (VOID*)&recv, RK_NO_WAIT) ==
RK_ERR_SUCCESS)
{
logPost("Q%u <- sender=%s payload=%u", i,
RK_TASK_NAME(recv.producer), recv.payload);
}
}
}
}
} 0 ms :: Q1 <- sender=Prod1 payload=0
250 ms :: Q0 <- sender=Prod0 payload=1
500 ms :: Q0 <- sender=Prod0 payload=2
600 ms :: Q1 <- sender=Prod1 payload=1
750 ms :: Q0 <- sender=Prod0 payload=3
1000 ms :: Q0 <- sender=Prod0 payload=4
1200 ms :: Q1 <- sender=Prod1 payload=2
1250 ms :: Q0 <- sender=Prod0 payload=5
1500 ms :: Q0 <- sender=Prod0 payload=6
1750 ms :: Q0 <- sender=Prod0 payload=7
1800 ms :: Q1 <- sender=Prod1 payload=3
1800 ms :: Q2 <- sender=Prod1 payload=4
2000 ms :: Q0 <- sender=Prod0 payload=8
2250 ms :: Q0 <- sender=Prod0 payload=9
2400 ms :: Q1 <- sender=Prod1 payload=4
2500 ms :: Q0 <- sender=Prod0 payload=10
2750 ms :: Q0 <- sender=Prod0 payload=11
3000 ms :: Q0 <- sender=Prod0 payload=12
3000 ms :: Q1 <- sender=Prod1 payload=5
3250 ms :: Q0 <- sender=Prod0 payload=13
3500 ms :: Q0 <- sender=Prod0 payload=14
3600 ms :: Q1 <- sender=Prod1 payload=6
3750 ms :: Q0 <- sender=Prod0 payload=15
4000 ms :: Q0 <- sender=Prod0 payload=16
4200 ms :: Q1 <- sender=Prod1 payload=7
4200 ms :: Q2 <- sender=Prod1 payload=8
4250 ms :: Q0 <- sender=Prod0 payload=17
4500 ms :: Q0 <- sender=Prod0 payload=18
4750 ms :: Q0 <- sender=Prod0 payload=19
4800 ms :: Q1 <- sender=Prod1 payload=8
5000 ms :: Q0 <- sender=Prod0 payload=20
5250 ms :: Q0 <- sender=Prod0 payload=219.8.6.3. Ports for Resource Management
A PORT naturally fits a resource-manager task. When senders block on a full PORT, the owner effective priority is raised to that of the highest-priority waiter, similarly to mutex priority inheritance.
Using a PORT for resource management is not invocation semantics (not a procedure call as in Call Channels): the owner is not executing on behalf of a caller stack frame. Any grant or completion is returned by a separate mechanism, such as an event flag.
A (counting) SEMAPHORE is the intuitive and less expensive choice to track resource credits. Since it has no ownership, it cannot by itself mitigate priority inversion. A mutex would be added.
A PORT can also represent bounded admission capacity while additionally providing ownership and priority inheritance under backpressure. In pure message-passing systems, modelling resource management as a task is idiomatic.
-
Case: Bursty contention:
-
Under nominal load, the PORT does not saturate and the manager task nominal priority is sufficient (DEPTH = 4 in this example).
-
It serves a sporadic high-priority task that is normally handled with low latency. In this example, jam() is used to insert urgent work at the queue head.
-
An abnormal medium-priority burst occurs and fills the queue.
-
Once the high-priority task blocks on the full queue, the PORT owner inherits its priority, reducing inversion time while backlog is being drained.
-
Once pressure vanishes and no higher-priority sender remains blocked, the owner priority returns to nominal.
-
/*
the kPort* API are macro wrappers of the message queue API that have queue's owner as the first parameter. just that. the Mesg Queue API still applies entirely, and there is no RK_PORT object.
for recv one uses kPortRecv with no taskhandle specified.
*/
typedef struct
{
UINT clientId;
UINT seq;
UINT channel;
UINT sample;
} DACReq_t;
/* client enqueue request for resource usage to the manager-owned PORT. */
static inline VOID DacClientSend(UINT cid, UINT seq, UINT ch, UINT val)
{
DACReq_t req = {.clientId = cid, .seq = seq, .channel = ch, .sample = val};
kPortSend(dacMgrHandle, &req, RK_WAIT_FOREVER);
}
/* insert on head for sporadic urgent task. */
static inline VOID DacClientJam(UINT cid, UINT seq, UINT ch, UINT val)
{
DACReq_t req = {.clientId = cid, .seq = seq, .channel = ch, .sample = val};
kPortJam(dacMgrHandle, &req, RK_WAIT_FOREVER);
}
/* Resource manager task */
VOID DacMgrTask(VOID *args)
{
RK_UNUSEARGS
DACReq_t req = {0};
while (1)
{
RK_PRIO const pBefore = kTaskGetPrio(dacMgrHandle);
kPortRecv(&req, RK_WAIT_FOREVER);
/* how to grant the resource is an application concern */
grantResource_(req.clientId, req.sample);
RK_PRIO const pAfter = kTaskGetPrio(dacMgrHandle);
printf("%8lu ms :: DACMGR APPLIED d%u_%u ch%u=%u (mgrP=%u->%u)\r\n",
kTickGetMs(), req.clientId, req.seq, req.channel, req.sample,
pBefore, pAfter);
kSleep(RK_MS_TO_TICKS(80));
}
}The example is 3 clients using multi-channel DAC. The log captures a burst window of client 2 (medium priority):
330 ms :: DACMGR APPLIED d2_4 ch1=704 (mgrP=2->2/2)
330 ms :: CLIENT c2 ENQ d2_8 wait=80 ms // note it granted request 4, and just admitted request 8. Queue is full.
330 ms :: CLIENT c2 REQ d2_9
400 ms :: CLIENT c3 REQ d3_1
410 ms :: DACMGR APPLIED d2_5 ch1=705 (mgrP=2->2/2) //applied c2 req5
410 ms :: CLIENT c2 ENQ d2_9 wait=80 ms // after 80ms admitted c2 req9
410 ms :: CLIENT c2 REQ d2_10
490 ms :: DACMGR APPLIED d2_6 ch1=706 (mgrP=2->2/2) /
490 ms :: CLIENT c2 ENQ d2_10 wait=80 ms
570 ms :: DACMGR APPLIED d2_7 ch1=707 (mgrP=2->2/2)
570 ms :: CLIENT c3 ENQ d3_1 wait=170 ms
610 ms :: CLIENT c1 REQ d1_2 // <- HIGH PRIO TASK HITS A FULL QUEUE
650 ms :: CLIENT c1 ENQ d1_2 wait=40 ms // <- high priority enqueued.
650 ms :: DACMGR APPLIED d2_8 ch1=708 (mgrP=1->2/2 q=4) // PRIORITY WAS BOOSTED
730 ms :: DACMGR APPLIED d1_2 ch0=1002 (mgrP=2->2) // PRIORITY RESTOREDWhen the queue is full and a higher-priority sender blocks, the PORT owner inherits the head waiter priority. After backlog clears, the owner returns to nominal priority.
9.9. Call Channels (procedure calls)
Channels (RK_CHANNEL) implement client‑blocking procedure calls. Each client
enqueues a request pointer and blocks until the server completes that request.
Multiple clients can be pending at once. The server processes requests and
completes them with kChannelDone().
Each Channel has a request-envelope pool. An envelope carries sender metadata
and application pointers for request and response payloads. Requesters blocked
in kChannelCall() are tracked by the channel itself and are dequeued and readied
when kChannelDone() runs. While servicing a call, the server adopts the
client’s priority and restores its nominal priority after done().
| Channel Control Block |
|---|
Ring Buffer (request pointers) |
Server Task |
Waiting Receivers |
Waiting Requesters |
Request Pool |
A RK_REQ_BUF is a request envelope, which is a structure that
contains metadata about the sender and pointers to the request and response payloads.
The channel has a pool of these envelopes, and clients must allocate one to make a call.
| Request Buffer |
|---|
Server Task |
Pointer to Request Payload |
Size of Request Payload |
Pointer to Response Buffer |
9.9.1. Usage Example: HVAC Control System
Note supervisor and sensor tasks are periodic and the actuator task is event-driven by the procedure call.

/**
*
* APDU request frame (supervisor -> actuator):
* INSTRUCTION | PAYLOADSIZE | PAYLOAD | CRC16
*
* Control payload layout:
* SETPOINT_C | CURRENT_TEMP_C | FAN_SPEED_% | OCCUPANCY(0/1)
*
* OCCUPANCY :
* 0 = no presence (energy-saving allowed)
* 1 = (comfort mode)
*
* Response (actuator -> supervisor):
* CRC16
*
* Control-system idea:
* - Setpoint is fixed and stable at 24C.
* - Sensor tasks produce current temperature and occupancy.
* - A supervisor task reads those inputs and computes fan speed.
* - The supervisor sends one control frame:
* {SETPOINT, CURRENT_TEMP, FAN_SPEED, OCCUPANCY}.
* - A single actuator task owns power delivery and applies every command.
* - CHANNEL calls serialise updates, so plant transitions are deterministic.
* - Sensor tasks are periodic (kSleepRelease()).
* - Supervisor is periodic but has a time-bounded call() to the actuator.
* - The actuator is event-driven and progresses based on kChannelAccept(),
* interactions, and task priorities.
* - The response CRC is an acknowledgement fingerprint of
* {instruction, execution-result, current actuator state}.
*/
#include <kapi.h>
#include <logger.h>
#include <stdlib.h>
#define STACKSIZE 256
#define TEMP_SENSOR_PERIOD 150U
#define OCC_SENSOR_PERIOD 180U
#define SUPERVISOR_PERIOD 100U
/* workarounds to change occupancy faster */
#define OCC_PRESENT_TO_EMPTY_CHANCE_PCT 35U
#define OCC_EMPTY_TO_PRESENT_CHANCE_PCT 45U
#define OCC_MAX_PRESENT_DWELL_SAMPLES 3U
#define OCC_MAX_EMPTY_DWELL_SAMPLES 2U
#define HVAC_CHANNEL_DEPTH 4U /* max number of pending requests */
#define HVAC_APDU_MAX_PAYLOAD 8U /* max payload size in bytes */
#define HVAC_SETPOINT_C ((BYTE)24U)
/* instruction */
#define HVAC_INS_APPLY_CONTROL ((BYTE)0x30U)
/* control payload fields */
#define HVAC_CONTROL_PAYLOAD_SIZE ((BYTE)4U)
#define HVAC_PAYLOAD_SETPOINT_IDX 0U
#define HVAC_PAYLOAD_CURRENT_IDX 1U
#define HVAC_PAYLOAD_FAN_IDX 2U
#define HVAC_PAYLOAD_OCCUPANCY_IDX 3U
/* occupancy is a binary signal, not a people count */
#define HVAC_OCCUPANCY_EMPTY ((BYTE)0U)
#define HVAC_OCCUPANCY_PRESENT ((BYTE)1U)
/* limits */
#define HVAC_MIN_TEMP_C ((BYTE)16U)
#define HVAC_MAX_TEMP_C ((BYTE)35U)
typedef struct
{
BYTE instruction;
BYTE payloadSize;
BYTE payload[HVAC_APDU_MAX_PAYLOAD];
USHORT crc;
} HVAC_APDU;
typedef struct
{
BYTE setpointC;
BYTE currentTempC;
BYTE fanPercent;
BYTE occupancy;
BYTE powerPercent;
} HVAC_STATE;
typedef struct
{
RK_MUTEX lock;
BYTE currentTempC;
BYTE occupancy;
} HVAC_INPUTS;
/* sensing + supervisor + single actuator */
RK_DECLARE_TASK(tempSensorHandle, TempSensorTask, tempSensorStack, STACKSIZE)
RK_DECLARE_TASK(occupancySensorHandle, OccupancySensorTask,
occupancySensorStack, STACKSIZE)
RK_DECLARE_TASK(supervisorHandle, SupervisorTask, supervisorStack, STACKSIZE)
RK_DECLARE_TASK(hvacActuatorHandle, HvacActuatorTask, hvacActuatorStack,
STACKSIZE)
/* declare the channel and the buffer to enqueue the requests */
static RK_CHANNEL hvacChannel;
RK_DECLARE_CHANNEL_BUF(hvacChannelBuf, HVAC_CHANNEL_DEPTH)
/* request pool for the channel */
static RK_MEM_PARTITION hvacReqPartition;
static RK_REQ_BUF hvacReqPool[HVAC_CHANNEL_DEPTH] K_ALIGN(4);
static HVAC_INPUTS hvacInputs;
/* local methods - not shown for brevity */
static VOID HvacInputsInit_(VOID)
{
RK_ERR err = kMutexInit(&hvacInputs.lock, RK_INHERIT);
K_ASSERT(err == RK_ERR_SUCCESS);
hvacInputs.currentTempC = HVAC_SETPOINT_C;
hvacInputs.occupancy = HVAC_OCCUPANCY_PRESENT;
}
static USHORT HvacCrc16Ccitt_(BYTE const *const dataPtr, UINT const len);
static USHORT HvacBuildApduCrc_(HVAC_APDU const *const apduPtr);
static USHORT HvacBuildResponseCrc_(BYTE const instruction,
RK_BOOL const executed,
HVAC_STATE const *const statePtr);
static BYTE HvacComputePowerPercent_(BYTE const setpointC,
BYTE const currentTempC,
BYTE const fanPercent,
BYTE const occupancy);
static RK_BOOL HvacExecuteInstruction_(HVAC_APDU const *const apduPtr,
HVAC_STATE *const statePtr);
static VOID HvacInputsSetTemp_(BYTE const tempC);
static VOID HvacInputsSetOccupancy_(BYTE const occupancy);
static VOID HvacInputsGet_(BYTE *const tempCPtr, BYTE *const occupancyPtr);
static BYTE HvacClampTempC_(INT const value);
static BYTE HvacComputeFanPercent_(BYTE const currentTempC, BYTE const occupancy);
/* this is shown to stress the need to allocate a request buffer */
static RK_ERR HvacControlCall_(BYTE const setpointC,
BYTE const currentTempC,
BYTE const fanPercent,
BYTE const occupancy,
RK_TICK const timeout,
USHORT *const responseCrcPtr)
{
HVAC_APDU apdu = {0};
RK_REQ_BUF *reqBuf =
(RK_REQ_BUF *)kMemPartitionAlloc(&hvacReqPartition);
K_ASSERT(reqBuf != NULL);
K_ASSERT(responseCrcPtr != NULL);
apdu.instruction = HVAC_INS_APPLY_CONTROL;
apdu.payloadSize = HVAC_CONTROL_PAYLOAD_SIZE;
apdu.payload[HVAC_PAYLOAD_SETPOINT_IDX] = setpointC;
apdu.payload[HVAC_PAYLOAD_CURRENT_IDX] = currentTempC;
apdu.payload[HVAC_PAYLOAD_FAN_IDX] = fanPercent;
apdu.payload[HVAC_PAYLOAD_OCCUPANCY_IDX] = occupancy;
apdu.crc = HvacBuildApduCrc_(&apdu);
reqBuf->size = (ULONG)sizeof(HVAC_APDU);
reqBuf->reqPtr = &apdu;
reqBuf->respPtr = responseCrcPtr;
return (kChannelCall(hvacActuatorHandle, reqBuf, timeout));
}
/* Tasks */
/*prio: 4*/
VOID HvacActuatorTask(VOID *args)
{
RK_UNUSEARGS
/* single-writer plant model */
HVAC_STATE hvacState =
{
.setpointC = HVAC_SETPOINT_C,
.currentTempC = HVAC_SETPOINT_C,
.fanPercent = 20U,
.occupancy = HVAC_OCCUPANCY_PRESENT,
.powerPercent = 20U
};
while (1)
{
RK_REQ_BUF *reqBuf = NULL;
RK_ERR err = kChannelAccept(&hvacChannel, &reqBuf, RK_WAIT_FOREVER);
K_ASSERT(err == RK_ERR_SUCCESS);
HVAC_APDU const *apduPtr = (HVAC_APDU const *)reqBuf->reqPtr;
USHORT *responseCrcPtr = (USHORT *)reqBuf->respPtr;
K_ASSERT(apduPtr != NULL);
K_ASSERT(responseCrcPtr != NULL);
RK_BOOL valid = (RK_BOOL)(reqBuf->size == (ULONG)sizeof(HVAC_APDU));
RK_BOOL executed = RK_FALSE;
if (valid != RK_FALSE)
{
USHORT expectedCrc = HvacBuildApduCrc_(apduPtr);
/* verify message is not corrupted */
valid = (RK_BOOL)(expectedCrc == apduPtr->crc);
}
if (valid != RK_FALSE)
{
executed = HvacExecuteInstruction_(apduPtr, &hvacState);
}
*responseCrcPtr = HvacBuildResponseCrc_(apduPtr->instruction,
executed,
&hvacState);
if ((valid != RK_FALSE) && (executed != RK_FALSE))
{
logPost("[ACTUATOR] SET=%uC CUR=%uC FAN=%u%% OCC=%u PWR=%u%% RESP_CRC=0x%04x",
(UINT)hvacState.setpointC,
(UINT)hvacState.currentTempC,
(UINT)hvacState.fanPercent,
(UINT)hvacState.occupancy,
(UINT)hvacState.powerPercent,
(UINT)(*responseCrcPtr));
}
else
{
logPost("[ACTUATOR] INVALID INS=0x%02x REQ_CRC=0x%04x RESP_CRC=0x%04x",
(UINT)apduPtr->instruction,
(UINT)apduPtr->crc,
(UINT)(*responseCrcPtr));
}
err = kChannelDone(reqBuf);
K_ASSERT(err == RK_ERR_SUCCESS);
}
}
/*prio: 2*/
VOID TempSensorTask(VOID *args)
{
RK_UNUSEARGS
BYTE tempC = (BYTE)(HVAC_SETPOINT_C + 7U); /* start above setpoint */
while (1)
{
/* pseudo-random temperature around setpoint with bounded drift */
INT const randomStep = (INT)((rand() % 3) - 1); /* -1..+1 */
INT biasStep = 0;
INT const errorC = (INT)HVAC_SETPOINT_C - (INT)tempC;
if ((rand() % 100) < 70)
{
if (errorC > 0)
{
biasStep = 1;
}
else if (errorC < 0)
{
biasStep = -1;
}
}
tempC = HvacClampTempC_((INT)tempC + randomStep + biasStep);
HvacInputsSetTemp_(tempC);
logPost("[TEMP ] SAMPLE=%uC", (UINT)tempC);
kSleepRelease(TEMP_SENSOR_PERIOD);
}
}
/* prio: 3 */
VOID OccupancySensorTask(VOID *args)
{
RK_UNUSEARGS
BYTE occupancy = HVAC_OCCUPANCY_PRESENT;
UINT dwellSamples = 0U;
while (1)
{
/*
* dwell for state changes faster
*/
dwellSamples++;
/* use stdlib.h */
UINT const chance = (UINT)(rand() % 100);
if (occupancy == HVAC_OCCUPANCY_PRESENT)
{
if ((chance < OCC_PRESENT_TO_EMPTY_CHANCE_PCT) ||
(dwellSamples >= OCC_MAX_PRESENT_DWELL_SAMPLES))
{
occupancy = HVAC_OCCUPANCY_EMPTY;
dwellSamples = 0U;
}
}
else if ((chance < OCC_EMPTY_TO_PRESENT_CHANCE_PCT) ||
(dwellSamples >= OCC_MAX_EMPTY_DWELL_SAMPLES))
{
occupancy = HVAC_OCCUPANCY_PRESENT;
dwellSamples = 0U;
}
HvacInputsSetOccupancy_(occupancy);
logPost("[OCCUP] SAMPLE=%u", (UINT)occupancy);
kSleepRelease(OCC_SENSOR_PERIOD);
}
}
/* prio: 1 */
VOID SupervisorTask(VOID *args)
{
RK_UNUSEARGS
while (1)
{
BYTE currentTempC = HVAC_SETPOINT_C;
BYTE occupancy = HVAC_OCCUPANCY_EMPTY;
HvacInputsGet_(¤tTempC, &occupancy);
BYTE fanPercent = HvacComputeFanPercent_(currentTempC, occupancy);
USHORT crc = 0U;
RK_ERR err = HvacControlCall_(HVAC_SETPOINT_C, currentTempC,
fanPercent, occupancy,
SUPERVISOR_PERIOD, &crc);
if (err == RK_ERR_SUCCESS)
{
logPost("[SUPERV] SET=%uC CUR=%uC FAN=%u%% OCC=%u RESP_CRC=0x%04x",
(UINT)HVAC_SETPOINT_C,
(UINT)currentTempC,
(UINT)fanPercent,
(UINT)occupancy,
(UINT)crc);
}
else
{ if (err == RK_ERR_TIMEOUT)
{
logPost("[SUPERV] TIMEOUT");
}
else
{
logError("[SUPERV] ERROR %d SET=%uC CUR=%uC FAN=%u%% OCC=%u",
err,
(UINT)HVAC_SETPOINT_C,
(UINT)currentTempC,
(UINT)fanPercent,
(UINT)occupancy);
}
}
RK_ERR errsl = kSleepRelease(SUPERVISOR_PERIOD);
K_ASSERT(errsl == RK_ERR_SUCCESS);
}
} 0 ms :: [TEMP ] SAMPLE=28C
0 ms :: [OCCUP] SAMPLE=1
0 ms :: [ACTUATOR] SET=24C CUR=24C FAN=35% OCC=1 PWR=20% RESP_CRC=0xcbe2
0 ms :: [SUPERV] SET=24C CUR=24C FAN=35% OCC=1 RESP_CRC=0xcbe2
1000 ms :: [ACTUATOR] SET=24C CUR=28C FAN=80% OCC=1 PWR=100% RESP_CRC=0xfedc
1000 ms :: [SUPERV] SET=24C CUR=28C FAN=80% OCC=1 RESP_CRC=0xfedc
1500 ms :: [TEMP ] SAMPLE=27C
1800 ms :: [OCCUP] SAMPLE=1
2000 ms :: [ACTUATOR] SET=24C CUR=27C FAN=65% OCC=1 PWR=96% RESP_CRC=0x9b26
2000 ms :: [SUPERV] SET=24C CUR=27C FAN=65% OCC=1 RESP_CRC=0x9b26
3000 ms :: [TEMP ] SAMPLE=26C
3000 ms :: [ACTUATOR] SET=24C CUR=27C FAN=65% OCC=1 PWR=96% RESP_CRC=0x9b26
3000 ms :: [SUPERV] SET=24C CUR=27C FAN=65% OCC=1 RESP_CRC=0x9b26
3600 ms :: [OCCUP] SAMPLE=0
4000 ms :: [ACTUATOR] SET=24C CUR=26C FAN=50% OCC=0 PWR=30% RESP_CRC=0xc0a2
4000 ms :: [SUPERV] SET=24C CUR=26C FAN=50% OCC=0 RESP_CRC=0xc0a2
4500 ms :: [TEMP ] SAMPLE=24C
5000 ms :: [ACTUATOR] SET=24C CUR=24C FAN=15% OCC=0 PWR=5% RESP_CRC=0x0964
5000 ms :: [SUPERV] SET=24C CUR=24C FAN=15% OCC=0 RESP_CRC=0x0964
5400 ms :: [OCCUP] SAMPLE=0
6000 ms :: [TEMP ] SAMPLE=24C
6000 ms :: [ACTUATOR] SET=24C CUR=24C FAN=15% OCC=0 PWR=5% RESP_CRC=0x0964
6000 ms :: [SUPERV] SET=24C CUR=24C FAN=15% OCC=0 RESP_CRC=0x0964
7000 ms :: [ACTUATOR] SET=24C CUR=24C FAN=15% OCC=0 PWR=5% RESP_CRC=0x0964
7000 ms :: [SUPERV] SET=24C CUR=24C FAN=15% OCC=0 RESP_CRC=0x0964
7200 ms :: [OCCUP] SAMPLE=1
7500 ms :: [TEMP ] SAMPLE=23C
8000 ms :: [ACTUATOR] SET=24C CUR=23C FAN=35% OCC=1 PWR=45% RESP_CRC=0xb876
8000 ms :: [SUPERV] SET=24C CUR=23C FAN=35% OCC=1 RESP_CRC=0xb876
9000 ms :: [TEMP ] SAMPLE=24C
9000 ms :: [OCCUP] SAMPLE=1
9000 ms :: [ACTUATOR] SET=24C CUR=23C FAN=35% OCC=1 PWR=45% RESP_CRC=0xb876
9000 ms :: [SUPERV] SET=24C CUR=23C FAN=35% OCC=1 RESP_CRC=0xb876
10000 ms :: [ACTUATOR] SET=24C CUR=24C FAN=35% OCC=1 PWR=20% RESP_CRC=0xcbe2
10000 ms :: [SUPERV] SET=24C CUR=24C FAN=35% OCC=1 RESP_CRC=0xcbe2
10500 ms :: [TEMP ] SAMPLE=23C
10800 ms :: [OCCUP] SAMPLE=1
11000 ms :: [ACTUATOR] SET=24C CUR=23C FAN=35% OCC=1 PWR=45% RESP_CRC=0xb876
11000 ms :: [SUPERV] SET=24C CUR=23C FAN=35% OCC=1 RESP_CRC=0xb876
12000 ms :: [TEMP ] SAMPLE=23C
12000 ms :: [ACTUATOR] SET=24C CUR=23C FAN=35% OCC=1 PWR=45% RESP_CRC=0xb876
12000 ms :: [SUPERV] SET=24C CUR=23C FAN=35% OCC=1 RESP_CRC=0xb876
12600 ms :: [OCCUP] SAMPLE=0
13000 ms :: [ACTUATOR] SET=24C CUR=23C FAN=20% OCC=0 PWR=14% RESP_CRC=0xdf73
13000 ms :: [SUPERV] SET=24C CUR=23C FAN=20% OCC=0 RESP_CRC=0xdf73
13500 ms :: [TEMP ] SAMPLE=23C
14000 ms :: [ACTUATOR] SET=24C CUR=23C FAN=20% OCC=0 PWR=14% RESP_CRC=0xdf73
14000 ms :: [SUPERV] SET=24C CUR=23C FAN=20% OCC=0 RESP_CRC=0xdf73
14400 ms :: [OCCUP] SAMPLE=1
15000 ms :: [TEMP ] SAMPLE=23C9.10. Most-Recent Message Protocol (MRM)
| MRM Control Block |
|---|
MRM Buffer Allocator |
Data Buffer Allocator |
Current MRM Buffer Address |
Data Size (Message Size) |
| MRM Buffer |
|---|
Data Buffer Address |
Readers Count |
| Data Buffer |
|---|
Application-dependent |
|
There is little practical difference between a message that does not arrive and one with no valid (stale) data. But when wrong (or stale) data is processed - e.g., to define a set point on a loop - a system can fail badly. Design Choice: provide a broadcast asynchronous message-passing scheme that guarantees data freshness and integrity for all readers. Benefits: The system has a mechanism to meet strict deadlines that cannot be predicted on design time. |
Control loops reacting to unpredictable time events—like a robot scanning an environment or a drive-by-wire system—require a different message-passing approach. Readers cannot "look at the past" and cannot block. The most recent data must be delivered non-blocking and have guaranteed integrity.
As owner-bound queues, the MRM is a high-level mechanism. It was chosen to be provided as a kernel service, given its distinctive nature and suitability for RK0 applications.
9.10.1. Functional Description
An MRM works as a 1-to-many asynchronous Mailbox - that enables several readers to get the most recent deposited message with no integrity issues. Whenever a reader reads an MRM buffer, it will find the most recent data transmitted. It can also be seen as an extension of the Double Buffer pattern for a 1:N communication.
The core idea of the MRM protocol is that readers can only access the buffer that is classified as the 'most recent buffer'. After a writer publish() a message, that will be the only message readers can get() — any former message being processed by a reader was grabbed before a new publish() - and, from now on, can only be unget(), eventually returning to the pool.
To clarify further, the communication steps are listed:
-
A producer first reserves an MRM Buffer - the reserved MRM Buffer is not available for reading until it is published.
-
A message buffer is allocated and filled, and its address is within an MRM Buffer. The producer publishes the message. From now on, it is the most recent message. Any former published buffer is no longer visible to new readers
-
A reader starts by getting an MRM Buffer. A
get()operation delivers a copy of the message to the reader’s scope. Importantly, this operation increases the number of readers associated to that MRM Buffer.
Before ending its cycle, the task releases (unget()) the buffer; on releasing, the kernel checks if the caller task is the last reader and if the buffer being released is not the current MRM Buffer.
If the above conditions are met, the unget() operation will return the MRM buffer to the pool. If there are more readers, OR if it is the current buffer, it remains available.
When the reserve operation detects that the most recent buffer still has readers, a new buffer is allocated to be written and published. If it has no readers, it is reused.
This way, the worst case is a sequence of publish() with no unget() at all — this would lead to the writer finding no buffer to reserve. This is prevented by making: N Buffers = N tasks + 1.
9.10.1.1. MRM Control Block Configuration
What might lead to some confusion when initialising an MRM Control Block is the need for two different pools:
-
One pool will be the storage for the MRM Buffers, which is the data structure for the mechanism.
-
Another pool is for the actual payload. The messages.
Both pools must have the same number of elements: the number of tasks communicating + 1.
-
The size of the data buffers is application-dependent - and is passed as a number of words. The minimal message size is 32-bit.
-
If using data structures, keep it aligned to 4 to take advantage of the performance of aligned memory.
9.10.1.2. Usage Example: Immediate state transfer (Car Speed)
Consider a modern car - speed changes is an event of interest for many modules. Let us consider three modules and how they should react when speed varies:
-
Cruiser Control: For the Cruiser Control, a speed increase might signify the driver wants manual control back, and it will likely turn off.
-
Windshield Wipers: If they are on, a speed change can affect the electric motor’s adjustments to the air resistance.
-
Radio: Speed changes reflect the aerodynamic noise - the radio volume might need adjustment.
As the variations are unpredictable, we need a mechanism to deliver the last speed in order of importance for all these modules. From highest to lowest priority we elencate Cruise, Wipers, and Radio. (Criteria: safety → comfort).
To emulate this scenario, we can write an application with a higher priority task that sleeps and wakes up at pseudo-random times to produce random values that represent the (unpredictable) speed changes.
The snippet below has 4 periodic tasks. Tasks are periodic using the kSleepRelease() primitive.
The producer publishes new data at a random interval, preempting whatever task is running at the moment.
Despite the randomness of the updates, the actuators should keep their rate while reading the most recent state, with no integrity issues.
typedef struct
{
UINT speed;
ULONG timeStamp;
} Mesg_t;
#define STACKSIZE 256
#define N_MRM (5) /* Number of MRMs N Tasks + 1 */
#define MRM_MESG_SIZE (sizeof(Mesg_t) / 4) /* In WORDS */
RK_MRM MRMCtl; /* MRM control block */
RK_MRM_BUF buf[N_MRM]; /* MRM pool */
Mesg_t data[N_MRM]; /* message data pool */
RK_DECLARE_TASK(speedSensorHandle, SpeedSensorTask, stack1, STACKSIZE)
RK_DECLARE_TASK(cruiserHandle, CruiserTask, stack2, STACKSIZE)
RK_DECLARE_TASK(wiperHandle, WiperTask, stack3, STACKSIZE)
RK_DECLARE_TASK(radioHandle, RadioTask, stack4, STACKSIZE)
volatile UINT seq = 0;
VOID kApplicationInit(VOID)
{
kTaskInit(&speedSensorHandle, SpeedSensorTask, RK_NO_ARGS, "SpeedTsk",
stack1, STACKSIZE, 1, RK_PREEMPT);
kTaskInit(&cruiserHandle, CruiserTask, RK_NO_ARGS, "CruiserTsk", stack2,
STACKSIZE, 2, RK_PREEMPT);
kTaskInit(&wiperHandle, WiperTask, RK_NO_ARGS, "WiperTsk", stack3,
STACKSIZE, 3, RK_PREEMPT);
kTaskInit(&radioHandle, RadioTask, RK_NO_ARGS, "RadioTsk", stack4,
STACKSIZE, 4, RK_PREEMPT);
kMRMInit(&MRMCtl, buf, data, N_MRM, MRM_MESG_SIZE);
logInit(5);
}
VOID SpeedSensorTask(VOID *args)
{
RK_UNUSEARGS
Mesg_t sendMesg = {0};
while (1)
{
RK_TICK sleepTicks = ((RK_TICK)rand() % 18) + 1;
kSleep(sleepTicks);
RK_TICK currTick = kTickGetMs();
UINT speedValue = (UINT)(rand() % 170) + 1;
sendMesg.speed = speedValue;
sendMesg.timeStamp = currTick;
/* grab a buffer */
RK_MRM_BUF *bufPtr = kMRMReserve(&MRMCtl);
if (bufPtr != NULL)
{
K_ASSERT(!kMRMPublish(&MRMCtl, bufPtr, &sendMesg));
printf("!!!!! @%lums SPEED UPDATE: %u mph\r\n", kTickGetMs(), speedValue);
seq += 1;
}
else
{ /* cannot fail */
logError("MRM protocol could not find a free buffer\r\n");
}
/* publish */
}
}
VOID CruiserTask(VOID *args)
{
RK_UNUSEARGS
Mesg_t recvMesg = {0};
while (1)
{
RK_MRM_BUF *readBufPtr = kMRMGet(&MRMCtl, &recvMesg);
if (readBufPtr)
{
logPost("CRUISER: (%u mph, %lu ms)", recvMesg.speed, recvMesg.timeStamp);
kMRMUnget(&MRMCtl, readBufPtr);
}
kSleepRelease(4);
}
}
VOID WiperTask(VOID *args)
{
RK_UNUSEARGS
Mesg_t recvMesg = {0};
while (1)
{
RK_MRM_BUF *readBufPtr = kMRMGet(&MRMCtl, &recvMesg);
if (readBufPtr)
{
logPost("WIPERS: (%u mph, %lu ms)", recvMesg.speed, recvMesg.timeStamp);
kMRMUnget(&MRMCtl, readBufPtr);
}
kSleepRelease(7);
}
}
VOID RadioTask(VOID *args)
{
RK_UNUSEARGS
Mesg_t recvMesg = {0};
while (1)
{
RK_MRM_BUF *readBufPtr = kMRMGet(&MRMCtl, &recvMesg);
if (readBufPtr)
{
logPost("RADIO: (%u mph, %lu ms) ", recvMesg.speed, recvMesg.timeStamp);
kMRMUnget(&MRMCtl, readBufPtr);
}
kSleepRelease(11);
}
}Thus, different situations can happen:
-
All tasks read the updated pair (speed, time)
-
Not all tasks receive the updated pair because another update happens in between.
-
No tasks receive an update - because another happens too soon.
-
No update happens between in the period of a given task. It receives the same value. No problems.
All these cases are on the log:
Logs show: (last speed record, record time)
!!!@120ms SPEED UPDATE: 164 mph
120 ms :: CRUISER: (164 mph, 120 ms)
140 ms :: WIPERS: (164 mph, 120 ms)
!!! @150ms SPEED UPDATE: 80 mph
160 ms :: CRUISER: (80 mph, 150 ms)
200 ms :: CRUISER: (80 mph, 150 ms)
210 ms :: WIPERS: (80 mph, 150 ms)
220 ms :: RADIO: (80 mph, 150 ms)
240 ms :: CRUISER: (80 mph, 150 ms)
!!!@280ms SPEED UPDATE: 49 mph
280 ms :: CRUISER: (49 mph, 280 ms)
280 ms :: WIPERS: (49 mph, 280 ms)
320 ms :: CRUISER: (49 mph, 280 ms)
330 ms :: RADIO: (49 mph, 280 ms)
350 ms :: WIPERS: (49 mph, 280 ms)
360 ms :: CRUISER: (49 mph, 280 ms)
400 ms :: CRUISER: (49 mph, 280 ms)
420 ms :: WIPERS: (49 mph, 280 ms)
440 ms :: CRUISER: (49 mph, 280 ms)
440 ms :: RADIO: (49 mph, 280 ms)
!!!@450ms SPEED UPDATE: 87 mph
480 ms :: CRUISER: (87 mph, 450 ms)
490 ms :: WIPERS: (87 mph, 450 ms)
520 ms :: CRUISER: (87 mph, 450 ms)
!!! @540ms SPEED UPDATE: 110 mph
550 ms :: RADIO: (110 mph, 540 ms)
560 ms :: CRUISER: (110 mph, 540 ms)
560 ms :: WIPERS: (110 mph, 540 ms)
600 ms :: CRUISER: (110 mph, 540 ms)
630 ms :: WIPERS: (110 mph, 540 ms)
!!! @640ms SPEED UPDATE: 22 mph
640 ms :: CRUISER: (22 mph, 640 ms)
660 ms :: RADIO: (22 mph, 640 ms)The highlight is that controllers can keep their pace, while receiving fresh data - you can see it on the timestamp on the image.
Again, they might receive the same data more than once or miss samples; what is important is that they are not lagging and consuming stale data.
9.10.1.3. Usage Example: Cascaded Robot Servo Loop
This code illustrates a robot control system capable of exploring unknown objects by integrating visual and tactile information. In order to do so, the robot has to apply forces on the object surface and follow its contour by means of visual feedback.
The system is designed as 2 servo loops — which inputs are the current image frames (what the robot is seeing) and the current torque (the current force on its arm).
-
ForceTask: A sensory acquisition process periodically reads the force/torque sensor. This task runs @20ms, and if late the robot might become unstable by applying inadequate force/torque on the environment.
-
VisionTask: A visual process periodically reads the image memory filled by the camera frame grabber and computes the next exploring direction based on a user-defined strategy. A missed deadline for this task could cause the robot to move on a wrong direction or to stomp on the object object surface.
-
ControlTask: Based on computed path and required force, a robot control process computes the Cartesian set points for the controller. This information either moves the robot direction tangential to the object surface, or apply forces normal to the surface.
-
DisplayTask: A display task is used for telemetry. This is the less critical one in the sense that if late, quality of result degrades but nothing is damaged.
(Adapted from: Giorgio Buttazzo, Hard Real-Time Computing Systems (Chapter 11))
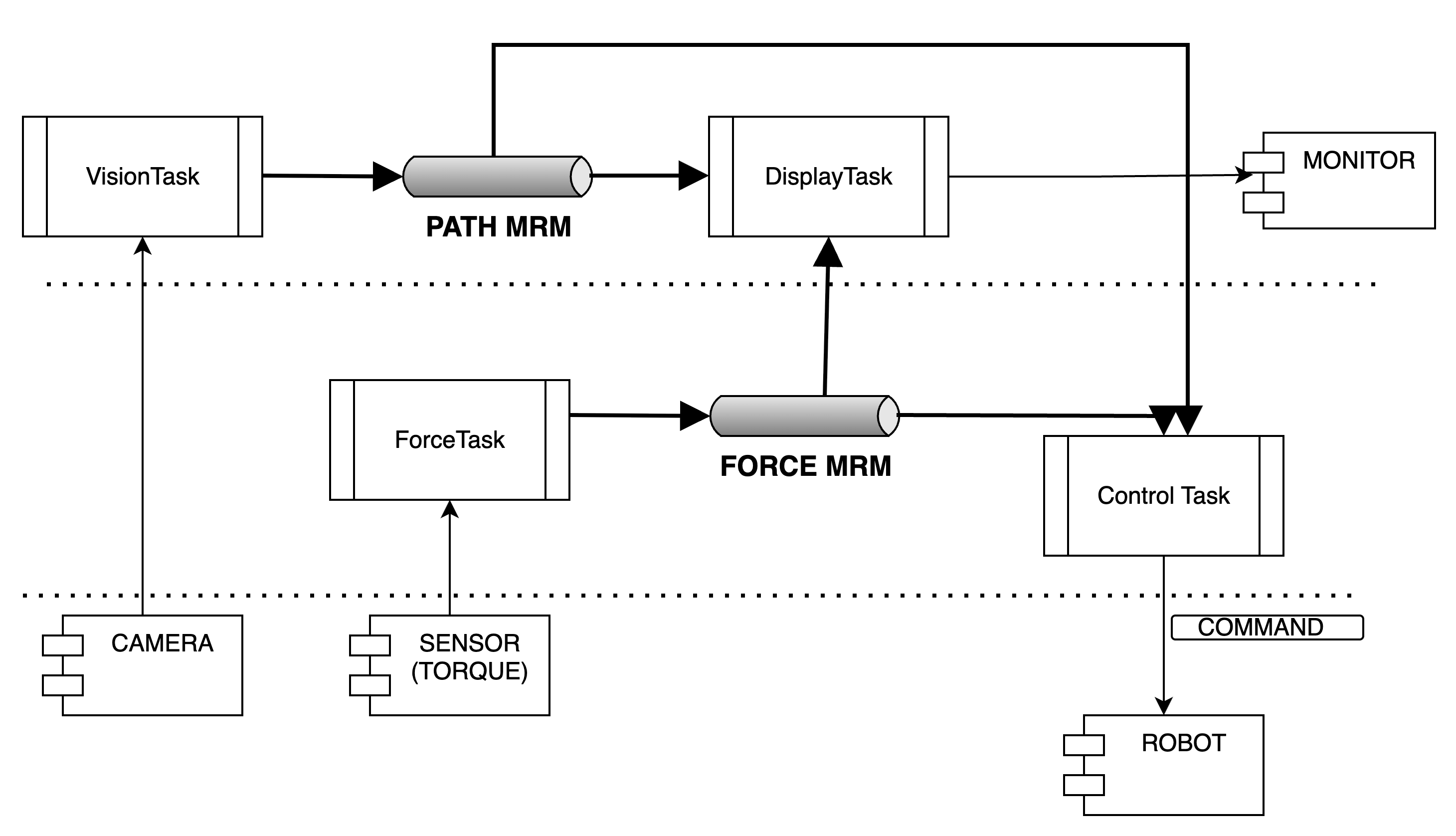
/* --- EXCERPT --- */
typedef struct
{
LONG normalForceMN; /* normal contact force [mN] */
LONG torqueMNm; /* wrist torque around x [mNm] */
UINT contact; /* binary contact flag */
RK_TICK tsMs; /* sample timestamp [ms] */
} FORCE_MRM_MESG;
typedef struct
{
LONG txMilli; /* tangential x component in milli-units (1000 -> 1.0) */
LONG tyMilli; /* tangential y component in milli-units (1000 -> 1.0) */
UINT strategy; /* selected exploration strategy/phase */
RK_TICK tsMs; /* sample timestamp [ms] */
} PATH_MRM_MESG;
typedef struct
{
LONG vxMmps; /* commanded tangential velocity x [mm/s] */
LONG vyMmps; /* commanded tangential velocity y [mm/s] */
LONG vzMmps; /* commanded normal velocity from force loop [mm/s] */
LONG xMm; /* integrated x position [mm] */
LONG yMm; /* integrated y position [mm] */
LONG zMm; /* integrated z position [mm] */
} ROBOT_CMD_MESG;
/* Two shared MRM channels: latest force and latest path guidance. */
static RK_MRM mrmForce;
static RK_MRM mrmPath;
/* priority assigned higher for the shortest period */
#define PERIOD_FORCE_MS 20U /* highest critical */
#define PERIOD_CONTROL_MS 28U /* middle critical */
#define PERIOD_VISION_MS 80U /* lowest critical */
#define PERIOD_DISPLAY_MS 100U /* soft real-time task */
VOID ForceTask(VOID *args)
{
RK_UNUSEARGS
while (1)
{
/* acquire simulated force sample and publish latest */
RK_TICK nowMs = kTickGetMs();
FORCE_MRM_MESG mesg = simulateForceSensor_(nowMs);
RK_ERR err = publishLatest_(&mrmForce, &mesg);
K_ASSERT(err == RK_ERR_SUCCESS);
logPost("[FORCE ] Fn=%ldmN T=%ldmNm contact=%u", mesg.normalForceMN,
mesg.torqueMNm, mesg.contact);
sleepHardTask_(periodForceTicks, "FORCE");
}
}
VOID VisionTask(VOID *args)
{
RK_UNUSEARGS
while (1)
{
/* compute next tangential direction and publish latest one */
RK_TICK nowMs = kTickGetMs();
PATH_MRM_MESG mesg = simulatePathFromVision_(nowMs);
RK_ERR err = publishLatest_(&mrmPath, &mesg);
K_ASSERT(err == RK_ERR_SUCCESS);
logPost("[VISION] path=(%ld,%ld) strategy=%u", mesg.txMilli,
mesg.tyMilli, mesg.strategy);
sleepHardTask_(periodVisionTicks, "VISION");
}
}
VOID ControlTask(VOID *args)
{
RK_UNUSEARGS
ROBOT_CMD_MESG cmd = {0};
while (1)
{
FORCE_MRM_MESG forceMsg;
PATH_MRM_MESG pathMsg;
/* read latest force/path snapshots */
RK_MRM_BUF *forceBufPtr = kMRMGet(&mrmForce, &forceMsg);
RK_MRM_BUF *pathBufPtr = kMRMGet(&mrmPath, &pathMsg);
while (forceBufPtr == NULL || pathBufPtr == NULL)
{
/* wait until initial samples are available. */
forceBufPtr = kMRMGet(&mrmForce, &forceMsg);
pathBufPtr = kMRMGet(&mrmPath, &pathMsg);
kSleep(1);
continue;
}
kMRMUnget(&mrmForce, forceBufPtr);
kMRMUnget(&mrmPath, pathBufPtr);
/* normal-axis loop: force error -> bounded z velocity command. */
LONG forceErr = FORCE_DES_MN - forceMsg.normalForceMN;
LONG vzMmps = clampLong_(forceErr / 20L, -60L, 60L);
/* tangential motion from vision direction vector in milli-units. */
LONG vxCmd = (pathMsg.txMilli * TANGENTIAL_VEL_MMPS) / 1000L;
LONG vyCmd = (pathMsg.tyMilli * TANGENTIAL_VEL_MMPS) / 1000L;
if (forceMsg.contact == 0U)
{
/* No contact: stop tangential exploration and approach surface. */
vxCmd = 0L;
vyCmd = 0L;
vzMmps = 30L;
}
cmd.vxMmps = vxCmd;
cmd.vyMmps = vyCmd;
cmd.vzMmps = vzMmps;
/* commanded velocities to a simple discrete position estimate. */
cmd.xMm += (vxCmd * (LONG)periodControlEffMs) / 1000L;
cmd.yMm += (vyCmd * (LONG)periodControlEffMs) / 1000L;
cmd.zMm += (vzMmps * (LONG)periodControlEffMs) / 1000L;
/* sim sensor closed-loop : higher positive vzMmps raises normal force. */
gSimNormalForceMN = clampLong_(
gSimNormalForceMN + (vzMmps * (LONG)periodControlEffMs) / 2L,
0L,
12000L);
logPost("[CONTROL] v=(%ld,%ld) vz=%ld Fn=%ld err=%ld pos=(%ld,%ld,%ld)",
cmd.vxMmps, cmd.vyMmps, cmd.vzMmps, forceMsg.normalForceMN,
forceErr, cmd.xMm, cmd.yMm, cmd.zMm);
sleepHardTask_(periodControlTicks, "CONTROL");
}
}
VOID DisplayTask(VOID *args)
{
RK_UNUSEARGS
RK_TICK anchor = kTickGet();
while (1)
{
FORCE_MRM_MESG forceMsg;
PATH_MRM_MESG pathMsg;
/* less critical task: consume latest state for telemetry/visualization only. */
RK_MRM_BUF *forceBufPtr = kMRMGet(&mrmForce, &forceMsg);
RK_MRM_BUF *pathBufPtr = kMRMGet(&mrmPath, &pathMsg);
kMRMUnget(&mrmForce, forceBufPtr);
kMRMUnget(&mrmPath, pathBufPtr);
logPost("[DISPLAY] Fn=%ld path=(%ld,%ld) ts=(%lu,%lu)",
forceMsg.normalForceMN, pathMsg.txMilli, pathMsg.tyMilli,
(ULONG)forceMsg.tsMs, (ULONG)pathMsg.tsMs);
kSleepUntil(&anchor, periodDisplayTicks);
}
} 0 ms :: [FORCE ] Fn=4300mN T=-350mNm contact=1
0 ms :: [VISION] path=(1000,0) strategy=0
0 ms :: [DISPLAY] Fn=4300 path=(1000,0) ts=(0,0)
2 ms :: [CONTROL] v=(80,0) vz=35 Fn=4300 err=700 pos=(2,0,0)
20 ms :: [FORCE ] Fn=4790mN T=-350mNm contact=1
28 ms :: [CONTROL] v=(80,0) vz=10 Fn=4790 err=210 pos=(4,0,0)
40 ms :: [FORCE ] Fn=5000mN T=-315mNm contact=1
56 ms :: [CONTROL] v=(80,0) vz=0 Fn=5000 err=0 pos=(6,0,0)
60 ms :: [FORCE ] Fn=5000mN T=-315mNm contact=1
80 ms :: [FORCE ] Fn=5070mN T=-280mNm contact=1
80 ms :: [VISION] path=(1000,0) strategy=0
84 ms :: [CONTROL] v=(80,0) vz=-3 Fn=5070 err=-70 pos=(8,0,0)
100 ms :: [FORCE ] Fn=5028mN T=-280mNm contact=1
100 ms :: [DISPLAY] Fn=5028 path=(1000,0) ts=(100,80)
112 ms :: [CONTROL] v=(80,0) vz=-1 Fn=5028 err=-28 pos=(10,0,0)
120 ms :: [FORCE ] Fn=5084mN T=-245mNm contact=1
140 ms :: [FORCE ] Fn=5084mN T=-245mNm contact=1
140 ms :: [CONTROL] v=(80,0) vz=-4 Fn=5084 err=-84 pos=(12,0,0)
160 ms :: [FORCE ] Fn=5098mN T=-210mNm contact=1
160 ms :: [VISION] path=(1000,0) strategy=0
168 ms :: [CONTROL] v=(80,0) vz=-4 Fn=5098 err=-98 pos=(14,0,0)
180 ms :: [FORCE ] Fn=5042mN T=-210mNm contact=1
196 ms :: [CONTROL] v=(80,0) vz=-2 Fn=5042 err=-42 pos=(16,0,0)
200 ms :: [FORCE ] Fn=5084mN T=-175mNm contact=1
200 ms :: [DISPLAY] Fn=5084 path=(1000,0) ts=(200,160)
220 ms :: [FORCE ] Fn=5084mN T=-175mNm contact=1
224 ms :: [CONTROL] v=(80,0) vz=-4 Fn=5084 err=-84 pos=(18,0,0)
240 ms :: [FORCE ] Fn=5098mN T=-140mNm contact=1
240 ms :: [VISION] path=(1000,0) strategy=0
252 ms :: [CONTROL] v=(80,0) vz=-4 Fn=5098 err=-98 pos=(20,0,0)
260 ms :: [FORCE ] Fn=5042mN T=-140mNm contact=1
280 ms :: [FORCE ] Fn=5112mN T=-105mNm contact=1
280 ms :: [CONTROL] v=(80,0) vz=-5 Fn=5112 err=-112 pos=(22,0,0)
300 ms :: [FORCE ] Fn=5042mN T=-105mNm contact=1
300 ms :: [DISPLAY] Fn=5042 path=(1000,0) ts=(300,240)
308 ms :: [CONTROL] v=(80,0) vz=-2 Fn=5042 err=-42 pos=(24,0,0)
.
.
.
30800 ms :: [VISION] path=(0,1000) strategy=1
30800 ms :: [DISPLAY] Fn=5112 path=(0,1000) ts=(30800,30800)
30820 ms :: [FORCE ] Fn=5042mN T=140mNm contact=1
30828 ms :: [CONTROL] v=(0,80) vz=-2 Fn=5042 err=-42 pos=(1116,1088,36)
30840 ms :: [FORCE ] Fn=5084mN T=175mNm contact=1
30856 ms :: [CONTROL] v=(0,80) vz=-4 Fn=5084 err=-84 pos=(1116,1090,36)
30860 ms :: [FORCE ] Fn=5028mN T=175mNm contact=1
30880 ms :: [FORCE ] Fn=5098mN T=210mNm contact=1
30880 ms :: [VISION] path=(0,1000) strategy=1
30884 ms :: [CONTROL] v=(0,80) vz=-4 Fn=5098 err=-98 pos=(1116,1092,36)
30900 ms :: [FORCE ] Fn=5042mN T=210mNm contact=1
30900 ms :: [DISPLAY] Fn=5042 path=(0,1000) ts=(30900,30880)
30912 ms :: [CONTROL] v=(0,80) vz=-2 Fn=5042 err=-42 pos=(1116,1094,36)
30920 ms :: [FORCE ] Fn=5084mN T=245mNm contact=1
30940 ms :: [FORCE ] Fn=5084mN T=245mNm contact=1
30940 ms :: [CONTROL] v=(0,80) vz=-4 Fn=5084 err=-84 pos=(1116,1096,36)
30960 ms :: [FORCE ] Fn=5098mN T=280mNm contact=1Interpreting the output:
From 30800 ms:
-
path=(0,1000) means direction is pure +Y, so controller sets v=(0,80) mm/s.
-
Control runs every 28 ms, so position update is: dy = (80 * 28) / 1000 = 2 mm (integer)
-
That is why y: 1088 → 1090 → 1092.
-
x stays 1116 because vx=0.
-
z command is small and negative (vz=-2, -4) since force is slightly above 5000 mN, but: dz = (vz * 28)/1000 truncates to 0. vz remains 36.
-
at 30900, ts = (30900, 30880) says the robot is using the Fn informed (at inst 30900) and the last path/strategy, which was @ 30880 ms.
While the simulation model used to exercise the control is naive, the log shows the cascaded server-control loop is answering to environment changes on a timely and ordered manner.
10. Error Handling
10.1. Fail fast
While tracing and error handling are yet to be largely improved (and that is when the 1.0.0 version will be released), currently RK0 employs a policy of failing fast in debug mode.
When Error Checking is enabled, every kernel call will be 'defensive', checking for correctness of parameters and invariants, null dereferences, etc.
In these cases is more useful to allow the first error to halt the execution by calling an Error Handler function to observe the program state.
A trace structure records the address of the running TCB, its current stack pointer, the link register (that is, the PC at kErrHandler was called), and a time stamp.
This record is on a .noinit RAM section, so it is visible if CPU resets. A fault code is stored in a global faultID and on the trace structure.
Developers can hook in custom behaviour.
If the kernel is configured to not halt on a fault, but Error Checking is enabled, functions will return negative values in case of an error.
On the other hand, when Error Checking is disabled or NDEBUG is defined nothing is checked, reducing code size and improving performance.
(Some deeper internal calls have assertion. For those, only NDEBUG defined ensures they are disabled.)
10.2. Stack Overflow
Stack overflow is detected (not prevented) using a "stack painting" with a sentinel word. Stack Overflow detection is enabled by defining the assembler preprocessor __KDEF_STACKOVFLW when compiling.
As a matter of fact, sizing your stack is something you must do diligently when programming a system. I would say a mechanism for stack overflow detection is on the bottom of the list of 'must-have' features.
One can take advantage of the static task model - it is possible to predict offline the deepest call within any task. The compiler flag -fstack-usage creates .su files indicating the depth of every function within a module. This is an example of compilation-unit output:
core/src/ksema.c:34:8:kSemaphoreInit 88 static
core/src/ksema.c:74:8:kSemaphorePend 96 static
core/src/ksema.c:189:8:kSemaphorePost 88 static
core/src/ksema.c:306:5:kSemaphoreQuery 40 static
core/src/kmutex.c:128:8:kMutexInit 16 static
core/src/kmutex.c:165:8:kMutexLock 120 static
core/src/kmutex.c:325:8:kMutexUnlock 96 static
core/src/kmutex.c:425:6:kMutexQuery 56 staticThese are the worst cases. Now, you identify the depth of the longest chain of calls for a task using these services and add a generous safety margin — 30%. The cap depends on your budget.
Importantly, you also have to size the System Stack. This initial size is defined in linker.ld by the symbol Min_Stack_Size. In this case, account for the depth of main(), kApplicationInit(), and all interrupt handlers; again, inspect the longest call chain depth. Assume interrupts always add to the worst static depth, and account for nested interrupts.
10.3. Deadlocks
Most deadlock avoidance patterns are unsuitable to our domain. We shall be disciplined. Here there is a golden rule.
-
Ordered Locking:
The golden rule for locking is acquiring resources in an unidirectional order throughout the entire application:
acquire(A);
acquire(B);
acquire(C);
.
.
.
release(C);
release(B);
release(A);This breaks circular waiting.
For instance:
TaskA:
wait(R1);
wait(R2);
/* critical section */
signal(R2);
signal(R1);
TaskB:
wait(R1);
wait(R2);
/* critical section */
signal(R2);
signal(R1);But, if:
TaskA:
wait(R1);
wait(R2);
.
.
TaskB:
wait(R2);
wait(R1);
.
.There are some possible outcomes:
-
Deadlock:
-
TaskA runs: acquires R1
-
TaskB runs: acquires R2
-
TaskA runs: tries to acquire R2 — blocked
-
TaskB runs: tries to acquire R1 — blocked
-
-
No deadlock:
-
TaskA runs: acquires R1
-
TaskA runs: acquires R2 (nobody is holding R2)
-
TaskA releases both; TaskB runs and acquires both (in either order)
-
Overall, there is no deadlock if tasks do not overlap in critical sections. That is why systems run for years without deadlocks and eventually: ploft.
© 2026 Antonio Giacomelli | All Rights Reserved | www.kernel0.org